4. Query Language Guide¶
4.1. Preface¶
4.1.1. Overview¶
This guide provides information about how to use the rasdaman database management system (in short: rasdaman). The document explains usage of the rasdaman Query Language.
Follow the instructions in this guide as you develop your application which makes use of rasdaman services. Explanations detail how to create type definitions and instances; how to retrieve information from databases; how to insert, manipulate, and delete data within databases.
4.1.2. Audience¶
The information in this manual is intended primarily for application developers; additionally, it can be useful for advanced users of rasdaman applications and for database administrators.
4.1.3. Rasdaman Documentation Set¶
This manual should be read in conjunction with the complete rasdaman documentation set which this guide is part of. The documentation set in its completeness covers all important information needed to work with the rasdaman system, such as programming and query access to databases, guidance to utilities such as raswct, release notes, and additional information on the rasdaman wiki.
4.2. Introduction¶
4.2.1. Multidimensional Data¶
In principle, any natural phenomenon becomes spatio-temporal array data of some specific dimensionality once it is sampled and quantised for storage and manipulation in a computer system; additionally, a variety of artificial sources such as simulators, image renderers, and data warehouse population tools generate array data. The common characteristic they all share is that a large set of large multidimensional arrays has to be maintained. We call such arrays multidimensional discrete data (or short: MDD) expressing the variety of dimensions and separating them from the conceptually different multidimensional vectorial data appearing in geo databases.
rasdaman is a domain-independent database management system (DBMS) which supports multidimensional arrays of any size and dimension and over freely definable cell types. Versatile interfaces allow rapid application deployment while a set of cutting-edge intelligent optimization techniques in the rasdaman server ensures fast, efficient access to large data sets, particularly in networked environments.
4.2.2. Rasdaman Overall Architecture¶
The rasdaman client/server DBMS has been designed using internationally approved standards wherever possible. The system follows a two-tier client/server architecture with query processing completely done in the server. Internally and invisible to the application, arrays are decomposed into smaller units which are maintained in a conventional DBMS, for our purposes called the base DBMS.
On the other hand, the base DBMS usually will hold alphanumeric data (such as metadata) besides the array data. Rasdaman offers means to establish references between arrays and alphanumeric data in both directions.
Hence, all multidimensional data go into the same physical database as the alphanumeric data, thereby considerably easing database maintenance (consistency, backup, etc.).

Figure 4.1 Embedding of rasdaman in IT infrastructure¶
Further information on application program interfacing, administration, and related topics is available in the other components of the rasdaman documentation set.
4.2.3. Interfaces¶
The syntactical elements explained in this document comprise the rasql language interface to rasdaman. There are several ways to actually enter such statements into the rasdaman system:
By using the rasql command-line tool to send queries to rasdaman and get back the results.
By developing an application program which uses the raslib/rasj function
oql_execute()to forward query strings to the rasdaman server and get back the results.
Developing applications using the client API is the subject of this document. Please refer to the C++ Developers Guide or Java Developers Guide of the rasdaman documentation set for further information.
4.2.4. rasql and Standard SQL¶
The declarative interface to the rasdaman system consists of the rasdaman Query Language, rasql, which supports retrieval, manipulation, and data definition.
Moreover, the rasdaman query language, rasql, is very similar - and in fact embeds into - standard SQL. With only slight adaptations, rasql has been standardized by ISO as 9075 SQL Part 15: MDA (Multi-Dimensional Arrays). Hence, if you are familiar with SQL, you will quickly be able to use rasql. Otherwise you may want to consult the introductory literature referenced at the end of this chapter.
4.2.5. Notational Conventions¶
The following notational conventions are used in this manual:
Program text (under this we also subsume queries in the document on
hand) is printed in a monotype font. Such text is further
differentiated into keywords and syntactic variables. Keywords like
struct are printed in boldface; they have to be typed in as is.
An optional clause is enclosed in brackets; an arbitrary
repetition is indicated through brackets and an ellipsis. Grammar alternatives
can be grouped in parentheses separated by a | symbol.
Example
selectresultListfromnamedCollection[ [ as ]collIterator] [ ,namedCollection[ [ as ]collIterator] ]... [ wherebooleanExp]
It is important not to mix the regular brackets [ and ] denoting
array access, trimming, etc., with the grammar brackets [ and ]
denoting optional clauses and repetition; in grammar excerpts the first case
is in double quotes. The same applies to parentheses.
Italics are used in the text to draw attention to the first instance of a defined term in the text. In this case, the font is the same as in the running text, not Courier as in code pieces.
4.3. Terminology¶
4.3.1. An Intuitive Definition¶
An array is a set of elements which are ordered in space. The space considered here is discretized, i.e., only integer coordinates are admitted. The number of integers needed to identify a particular position in this space is called the dimension (sometimes also referred to as dimensionality). Each array element, which is referred to as cell, is positioned in space through its coordinates.
A cell can contain a single value (such as an intensity value in case of grayscale images) or a composite value (such as integer triples for the red, green, and blue component of a color image). All cells share the same structure which is referred to as the array cell type or array base type.
Implicitly a neighborhood is defined among cells through their coordinates: incrementing or decrementing any component of a coordinate will lead to another point in space. However, not all points of this (infinite) space will actually house a cell. For each dimension, there is a lower and upper bound, and only within these limits array cells are allowed; we call this area the spatial domain of an array. In the end, arrays look like multidimensional rectangles with limits parallel to the coordinate axes. The database developer defines both spatial domain and cell type in the array type definition. Not all bounds have to be fixed during type definition time, though: It is possible to leave bounds open so that the array can dynamically grow and shrink over its lifetime.
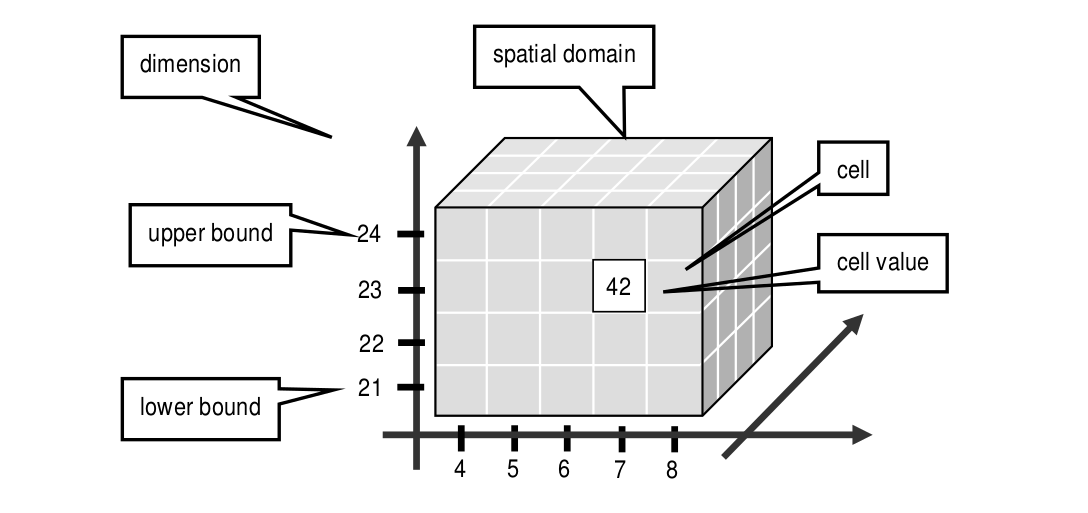
Figure 4.2 Constituents of an array¶
Synonyms for the term array are multidimensional array / MDA, multidimensional data / MDD, raster data, gridded data. They are used interchangeably in the rasdaman documentation.
In rasdaman databases, arrays are grouped into collections. All elements of a collection share the same array type definition (for the remaining degrees of freedom see Array types). Collections form the basis for array handling, just as tables do in relational database technology.
4.3.2. A Technical Definition¶
Programmers who are familiar with the concept of arrays in programming languages maybe prefer this more technical definition:
An array is a mapping from integer coordinates, the spatial domain, to some data type, the cell type. An array’s spatial domain, which is always finite, is described by a pair of lower bounds and upper bounds for each dimension, resp. Arrays, therefore, always cover a finite, axis-parallel subset of Euclidean space.
Cell types can be any of the base types and composite types defined in the ODMG standard and known, for example from C/C++. In fact, most admissible C/C++ types are admissible in the rasdaman type system, too.
In rasdaman, arrays are strictly typed wrt. spatial domain and cell type. Type checking is done at query evaluation time. Type checking can be disabled selectively for an arbitrary number of lower and upper bounds of an array, thereby allowing for arrays whose spatial domains vary over the array lifetime.
4.4. Sample Database¶
4.4.1. Collection mr¶
This section introduces sample collections used later in this manual. The sample database which is shipped together with the system contains the schema and the instances outlined in the sequel.
Collection mr consists of three images (see Figure 4.3) taken from the
same patient using magnetic resonance tomography. Images are 8 bit
grayscale with pixel values between 0 and 255 and a size of 256x211.
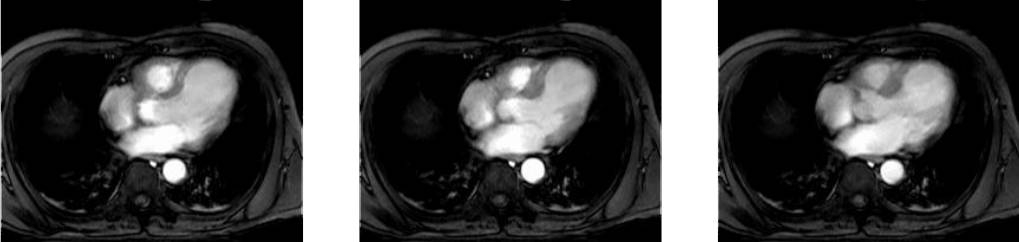
Figure 4.3 Sample collection mr¶
4.4.2. Collection mr2¶
Collection mr2 consists of only one image, namely the first image of
collection mr (Figure 4.4). Hence, it is also 8 bit grayscale with
size 256x211.
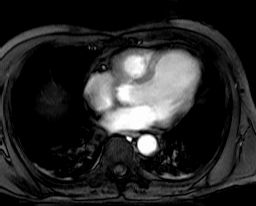
Figure 4.4 Sample collection mr2¶
4.4.3. Collection rgb¶
The last example collection, rgb, contains one item, a picture of the
anthur flower (Figure 4.5). It is an RGB image of size 400x344 where
each pixel is composed of three 8 bit integer components for the red, green, and
blue component, resp.

Figure 4.5 The collection rgb¶
4.5. Type Definition Using rasql¶
4.5.1. Overview¶
Every instance within a database is described by its data type (i.e., there is exactly one data type to which an instance belongs; conversely, one data type can serve to describe an arbitrary number of instances). Each database contains a self-contained set of such type definitions; no other type information, external to a database, is needed for database access.
Types in rasdaman establish a 3-level hierarchy:
Cell types can be atomic base types (such as char or float) or composite (“struct”) types such as red / green / blue color pixels.
Array types define arrays over some atomic or struct cell type and a spatial domain.
Set types describe sets of arrays of some particular array type.
Types are identified by their name which must be unique within a database and not exceed length of 200 characters. Like any other identifier in rasql queries, type names are case-sensitive, consist of only letters, digits, or underscore, and must start with a letter.
4.5.2. Cell types¶
4.5.2.1. Atomic types¶
The set of standard atomic types, which is generated during creation of a database, materializes the base types defined in the ODMG standard (cf. Table 4.1).
type name |
size |
description |
|---|---|---|
|
1 bit 2 |
true (nonzero value), false (zero value) |
|
8 bit |
signed integer |
|
8 bit |
unsigned integer |
|
16 bit |
signed integer |
|
16 bit |
unsigned integer |
|
32 bit |
signed integer |
|
32 bit |
unsigned integer |
|
32 bit |
single precision floating point |
|
64 bit |
double precision floating point |
|
32 bit |
complex of 16 bit signed integers |
|
64 bit |
complex of 32 bit signed integers |
|
64 bit |
single precision floating point complex |
|
128 bit |
double precision floating point complex |
4.5.2.2. Composite types¶
More complex, composite cell types can be defined arbitrarily, based on the system-defined atomic types. The syntax is as follows:
create type typeName
as (
attrName_1 atomicType_1,
...
attrName_n atomicType_n
)
Attribute names must be unique within a composite type, otherwise an
exception is thrown. No other type with the name typeName may pre-exist
already.
4.5.2.3. Example¶
An RGB pixel type can be defined as
create type RGBPixel
as (
red char,
green char,
blue char
)
4.5.3. Array types¶
An marray (“multidimensional array”) type defines an array type through its cell type (see Cell types) and a spatial domain.
4.5.3.1. Syntax¶
The syntax for creating an marray type is as below. There are two variants, corresponding to the dimensionality specification alternatives described above:
create type typeName
as baseTypeName mdarray domainSpec
where baseTypeName is the name of a defined cell type (atomic or composite)
and domainSpec is a multidimensional interval specification as described
in the following section.
Alternatively, a composite cell type can be indicated in-place:
create type typeName
as (
attrName_1 atomicType_1,
...
attrName_n atomicType_n
) mdarray domainSpec
No type (of any kind) with name typeName may pre-exist already,
otherwise an exception is thrown.
Attribute names must be unique within a composite type, otherwise an exception is thrown.
4.5.3.2. Spatial domain¶
Dimensions and their extents are specified by providing an axis name for each dimension and, optionally, a lower and upper bound:
[ a_1 ( lo_1 : hi_1 ), ... , a_d ( lo_d : hi_d ) ]
[ a_1 , ... , a_d ]
where d is a positive integer number, a_i are identifiers, and lo_1
and hi_1 are integers such that lo_1 \(\le\) hi_1. Both lo_1
and hi_1 can be an asterisk (*) instead of a number, in which case no
limit in the particular direction of the axis will be enforced. If the bounds
lo_1 and hi_1 on a particular axis are not specified, they are assumed
to be equivalent to *.
Axis names must be unique within a domain specification, otherwise an exception is thrown.
Currently axis names are ignored and cannot be used in queries yet.
4.5.3.3. Examples¶
The following statement defines a 2-D RGB image, based on the definition of
RGBPixel as shown above:
create type RGBImage
as RGBPixel mdarray [ x ( 0:1023 ), y ( 0:767 ) ]
An 2-D image without any extent limitation can be defined through:
create type UnboundedImage
as RGBPixel mdarray [ x, y ]
which is equivalent to
create type UnboundedImage
as RGBPixel mdarray [ x ( *:* ), y ( *:* ) ]
Selectively we can also limit only the bounds on the x axis for example:
create type PartiallyBoundedImage
as RGBPixel mdarray [ x ( 0 : 1023 ), y ]
4.5.4. Set types¶
A set type defines a collection of arrays sharing the same marray type. Additionally, a collection can also have null values which are used in order to characterise sparse arrays. A sparse array is an array where some of the elements have a null value.
4.5.4.1. Syntax¶
create type typeName
as set ( marrayTypeName [ nullValues ] )
where marrayTypeName is the name of a defined marray type and
nullValues is an optional specification of a set of values to be treated as
nulls; for semantics in operations refer to Null Values.
No type with the name typeName may pre-exist already.
4.5.4.2. Null Values¶
The optional nullValues clause in a set type definition is a set of null
value intervals:
null values [ nullInterval, ... ]
Each nullInterval can be a pair of lower and upper limits (1, 2, 3), or a
single (double) value (1):
lo : hi (1)
* : hi (2)
lo : * (3)
nullValue (4)
In case of an interval, the three variants are interpreted as follows:
Both
loandhiare double values such thatlo\(\le\)hi;lois*andhiis a double value, indicating that all values lower thanhiare null values;lois a double value andhiis*, indicating that all values greater thanloare null values.
For floating-point data it is recommended to always specify small intervals instead of single numbers with variant (4).
4.5.4.2.1. Limitation¶
Currently, only atomic null values can be indicated. They apply to all components of a composite cell simultaneously. In future it may become possible to indicate null values individually per struct component.
4.5.4.3. Examples¶
The following statement defines a set type of 2-D RGB images, based on the
definition of RGBImage:
create type RGBSet
as set ( RGBImage )
If values 0, 253, 254, and 255 are to be considered null values, this can be specified as follows:
create type RGBSet
as set ( RGBImage null values [ 0, 253 : 255 ] )
Note that these null values will apply equally to every band. It is not possible to separate null values per band.
As the cell type in this case is char (possible values between 0 and 255), the type can be equivalently specified like this:
create type RGBSet
as set ( RGBImage null values [ 0, 253 : * ] )
With the set type below, values which are nan are null values (nanf is the float constant, while nan is the double constant):
create type FloatSetNanNullValue
as set ( FloatImage null values [nanf] )
create type DoubleSetNanNullValue
as set ( DoubleImage null values [nan] )
4.5.5. Drop type¶
A type definition can be dropped (i.e., deleted from the database) if it is not in use. This is the case if both of the following conditions hold:
The type is not used in any other type definition.
There are no array instances existing which are based, directly or indirectly, on the type on hand.
Further, atomic base types (such as char) cannot be deleted.
Drop type syntax
drop type typeName
4.5.6. List available types¶
A list of all types defined in the database can be obtained in textual
form, adhering to the rasql type definition syntax. This is done by
querying virtual collections (similar to the virtual collection
RAS_COLLECTIONNAMES).
Technically, the output of such a query is a list of 1-D char arrays,
each one containing one type definition.
4.5.6.1. Syntax¶
select typeColl from typeColl
where typeColl is one of
RAS_STRUCT_TYPESfor struct typesRAS_MARRAY_TYPESfor array typesRAS_SET_TYPESfor set typesRAS_TYPESfor union of all types
Note
Collection aliases can be used, such as:
select t from RAS_STRUCT_TYPES as t
No operations can be performed on the output array.
4.5.6.2. Example output¶
A struct types result may look like this when printed:
create type RGBPixel
as ( red char, green char, blue char )
create type TestPixel
as ( band1 char, band2 char, band3 char )
create type GeostatPredictionPixel
as ( prediction float, variance float )
An marray types result may look like this when printed:
create type GreyImage
as char mdarray [ x, y ]
create type RGBCube
as RGBPixel mdarray [ x, y, z ]
create type XGAImage
as RGBPixel mdarray [ x ( 0 : 1023 ), y ( 0 : 767 ) ]
A set types result may look like this when printed:
create type GreySet
as set ( GreyImage )
create type NullValueTestSet
as set ( NullValueArrayTest null values [5:7] )
An all types result will print combination of all struct types, marray types, and set types results.
4.5.7. Changing types¶
The type of an existing collection can be changed to another type through
the alter statement.
The new collection type must be compatible with the old one, which means:
same cell type
same dimensionality
no domain shrinking
Changes are allowed, for example, in the null values.
Alter type syntax
alter collection collName
set type collType
where
collName is the name of an existing collection
collType is the name of an existing collection type
Usage notes
The collection does not need to be empty, i.e. it may contain array objects.
Currently, only set (i.e., collection) types can be modified.
Example
Update the set type of a collection Bathymetry to a new set type that
specifies null values:
alter collection Bathymetry
set type BathymetryWithNullValues
4.6. Query Execution with rasql¶
The rasdaman toolkit offers essentially a couple of ways to communicate with a database through queries:
By submitting queries via command line using rasql; this tool is covered in this section.
By writing a C++, Java, or Python application that uses the rasdaman APIs (raslib, rasj, or rasdapy3 respectively). See the rasdaman API guides for further details.
The rasql tool accepts a query string (which can be parametrised as explained in the API guides), sends it to the server for evaluation, and receives the result set. Results can be displayed in alphanumeric mode, or they can be stored in files.
4.6.1. Examples¶
For the user who is familiar with command line tools in general and the rasql query language, we give a brief introduction by way of examples. They outline the basic principles through common tasks.
Create a collection
testof typeGreySet(note the explicit setting of userrasadmin; rasql’s default userrasguestby default cannot write):rasql -q "create collection test GreySet" \ --user rasadmin --passwd rasadmin
Print the names of all existing collections:
rasql -q "select r from RAS_COLLECTIONNAMES as r" \ --out string
Export demo collection
mrinto TIFF files rasql_1.tif, rasql_2.tif, rasql_3.tif (note the escaped double-quotes as required by shell):rasql -q "select encode(m, \"tiff\") from mr as m" --out fileImport TIFF file myfile into collection
mras new image (note the different query string delimiters to preserve the$character!):rasql -q 'insert into mr values decode($1)' \ -f myfile --user rasadmin --passwd rasadmin
Put a grey square into every mr image:
rasql -q "update mr as m set m[0:10,0:10] \ assign marray x in [0:10,0:10] values 127c" \ --user rasadmin --passwd rasadmin
Verify result of update query by displaying pixel values as hex numbers:
rasql -q "select m[0:10,0:10] from mr as m" --out hex
4.6.2. Invocation syntax¶
Rasql is invoked as a command with the query string as parameter. Additional parameters guide detailed behavior, such as authentication and result display.
Any errors or other diagnostic output encountered are printed; transactions are aborted upon errors.
Usage:
rasql [--query q|-q q] [options]
Options:
- -h, --help
show command line switches
- -q, --query q
query string to be sent to the rasdaman server for execution
- -f, --file f
file name for upload through $i parameters within queries; each $i needs its own file parameter, in proper sequence 4. Requires –mdddomain and –mddtype
- --content
display result, if any (see also –out and –type for output formatting)
- --out t
use display method t for cell values of result MDDs where t is one of
none: do not display result item contents
file: write each result MDD into a separate file
string: print result MDD contents as char string (only for 1D arrays of type char)
hex: print result MDD cells as a sequence of space-separated hex values
formatted: reserved, not yet supported
Option –out implies –content; default: none
- --outfile of
file name template for storing result images (ignored for scalar results). Use ‘%d’ to indicate auto numbering position, like with printf(1). For well-known file types, a proper suffix is appended to the resulting file name. Implies –out file. (default: rasql_%d)
- --mdddomain d
MDD domain, format: ‘[x0:x1,y0:y1]’; required only if –file specified and file is in data format r_Array; if input file format is some standard data exchange format and the query uses a convertor, such as encode($1,”tiff”), then domain information can be obtained from the file header.
- --mddtype t
input MDD type (must be a type defined in the database); required only if –file specified and file is in data format r_Array; if input file format is some standard data exchange format and the query uses a convertor, such as decode($1,”tiff”), then type information can be obtained from the file header.
- --type
display type information for results
- -s, --server h
rasdaman server name or address (default: localhost)
- -p, --port p
rasdaman port number (default: 7001)
- -d, --database db
name of database (default: RASBASE)
- --user u
name of user (default: rasguest)
- --passwd p
password of user (default: rasguest). If this option is not specified, rasql will try to find a matching password in file
~/.raspassif it exists. This text file should containusername:passwordpairs, each one on a separate line, and it must have permissions u=rw (0600) or less (that is, at most read/writeable for the owner system user). If:characters appear in the password or username, they must be escaped with a backward slash\; e.g.username:pass\:wordwill be interpreted asusernamewith passwordpass:word. In case of multiple lines with matching username, rasql will pick the first one.- --quiet
print no ornament messages, only results and errors
4.7. Overview: General Query Format¶
4.7.1. Basic Query Mechanism¶
rasql provides declarative query functionality on collections (i.e., sets) of MDD stored in a rasdaman database. The query language is based on the SQL-92 standard and extends the language with high-level multidimensional operators.
The general query structure is best explained by means of an example. Consider the following query:
select mr[100:150,40:80] / 2
from mr
where some_cells( mr[120:160, 55:75] > 250 )
In the from clause, mr is specified as the working collection on which all evaluation will take place. This name, which serves as an “iterator variable” over this collection, can be used in other parts of the query for referencing the particular collection element under inspection.
Optionally, an alias name can be given to the collection (see syntax below) - however, in most cases this is not necessary.
In the where clause, a condition is phrased. Each collection element in turn is probed, and upon fulfillment of the condition the item is added to the query result set. In the example query, part of the image is tested against a threshold value.
Elements in the query result set, finally, can be “post-processed” in the select clause by applying further operations. In the case on hand, a spatial extraction is done combined with an intensity reduction on the extracted image part.
In summary, a rasql query returns a set fulfilling some search condition just as is the case with conventional SQL and OQL. The difference lies in the operations which are available in the select and where clause: SQL does not support expressions containing multidimensional operators, whereas rasql does.
Syntax
select resultList
from collName [ as collIterator ]
[ , collName [ as collIterator ] ] ...
[ where booleanExp ]
The complete rasql query syntax can be found in the Appendix.
4.7.2. Select Clause: Result Preparation¶
Type and format of the query result are specified in the select part of the query. The query result type can be multidimensional, a struct or atomic (i.e., scalar), or a spatial domain / interval. The select clause can reference the collection iteration variable defined in the from clause; each array in the collection will be assigned to this iteration variable successively.
Example
Images from collection mr, with pixel intensity reduced by a factor 2:
select mr / 2
from mr
4.7.3. From Clause: Collection Specification¶
In the from clause, the list of collections to be inspected is specified, optionally together with a variable name which is associated to each collection. For query evaluation the cross product between all participating collections is built which means that every possible combination of elements from all collections is evaluated. For instance in case of two collections, each MDD of the first collection is combined with each MDD of the second collection. Hence, combining a collection with n elements with a collection containing m elements results in n*m combinations. This is important for estimating query response time.
Example
The following example subtracts each MDD of collection mr2 from each MDD of collection mr (the binary induced operation used in this example is explained in Binary Induction).
select mr - mr2
from mr, mr2
Using alias variables a and b bound to collections mr and mr2, resp., the same query looks as follows:
select a - b
from mr as a, mr2 as b
Cross products
As in SQL, multiple collections in a from clause such as
from c1, c2, ..., ck
are evaluated to a cross product. This means that the select clause is evaluated for a virtual collection that has n1 * n2 * … * nk elements if c1 contains n1 elements, c2 contains n2 elements, and so forth.
Warning: This holds regardless of the select expression - even if you mention only say c1 in the select clause, the number of result elements will be the product of all collection sizes!
4.7.4. Where Clause: Conditions¶
In the where clause, conditions are specified which members of the query result set must fulfil. Like in SQL, predicates are built as boolean expressions using comparison, parenthesis, functions, etc. Unlike SQL, however, rasql offers mechanisms to express selection criteria on multidimensional items.
Example
We want to restrict the previous result to those images where at least one difference pixel value is greater than 50 (see Binary Induction):
select mr - mr2
from mr, mr2
where some_cells( mr - mr2 > 50 )
4.7.5. Comments in Queries¶
Comments are texts which are not evaluated by the rasdaman server in any way. However, they are useful - and should be used freely - for documentation purposes; in particular for stored queries it is important that its meaning will be clear to later readers.
Syntax
-- any text, delimited by end of line
Example
select mr -- this comment text is ignored by rasdaman
from mr -- for comments spanning several lines,
-- every line needs a separate '--' starter
4.8. Constants¶
4.8.1. Atomic Constants¶
Atomic constants are written in standard C/C++ style. If necessary constants are augmented with a one or two letter postfix to unambiguously determine its data type (Table 4.2).
The default for integer constants is l, and for floating-point it is d.
Specifiers are case insensitive.
Example
25c
-1700L
.4e-5D
Note
Boolean constants true and false are unique, so they do not need a type specifier.
postfix |
type |
|---|---|
o |
octet |
c |
char |
s |
short |
us |
unsigned short |
l |
long |
ul |
unsigned long |
f |
float |
d |
double |
Additionally, the following special floating-point constants are supported as well:
Constant |
Type |
|---|---|
NaN |
double |
NaNf |
float |
Inf |
double |
Inff |
float |
4.8.1.1. Complex numbers¶
Special built-in types are CFloat32 and CFloat64 for single and double
precision complex numbers, resp, as well as CInt16 and CInt32 for
signed integer complex numbers.
Syntax
complex( re, im )
where re and im are integer or floating point expressions. The resulting constant type is summarized on the table below. Further re/im type combinations are not supported.
type of re |
type of im |
type of complex constant |
|---|---|---|
short |
short |
CInt16 |
long |
long |
CInt32 |
float |
float |
CFloat32 |
double |
double |
CFloat64 |
Example
complex( .35d, 16.0d ) -- CFloat64
complex( .35f, 16.0f ) -- CFloat32
complex( 5s, 16s ) -- CInt16
complex( 5, 16 ) -- CInt32
Component access
The complex parts can be extracted with .re and .im; more details
can be found in the Induced Operations section.
4.8.2. Composite Constants¶
Composite constants resemble records (“structs”) over atomic constants or other records. Notation is as follows.
Syntax
struct { const_0, ..., const_n }
where const_i must be of atomic or complex type, i.e. nested structs are not supported.
Example
struct{ 0c, 0c, 0c } -- black pixel in an RGB image, for example
struct{ 1l, true } -- mixed component types
Component access
See Struct Component Selection for details on how to extract the constituents from a composite value.
4.8.3. Array Constants¶
Small array constants can be indicated literally. An array constant consists of the spatial domain specification (see Spatial Domain) followed by the cell values whereby value sequencing is as follow. The array is linearized in a way that the lowest dimension 5 is the “outermost” dimension and the highest dimension 6 is the “innermost” one. Within each dimension, elements are listed sequentially, starting with the lower bound and proceeding until the upper bound. List elements for the innermost dimension are separated by comma “,”, all others by semicolon “;”.
The exact number of values as specified in the leading spatial domain expression must be provided. All constants must have the same type; this will be the result array’s base type.
Syntax
< mintervalExp
scalarList_0 ; ... ; scalarList_n ; >
where scalarList is defined as a comma separated list of literals:
scalar_0, scalar_1, ... scalar_n ;
Example
< [-1:1,-2:2] 0, 1, 2, 3, 4;
1, 2, 3, 4, 5;
2, 3, 4, 5, 6 >
This constant expression defines the following matrix:

4.8.4. Object identifier (OID) Constants¶
OIDs serve to uniquely identify arrays (see Linking MDD with Other Data). Within a database, the OID of an array is an integer number. To use an OID outside the context of a particular database, it must be fully qualified with the system name where the database resides, the name of the database containing the array, and the local array OID.
The worldwide unique array identifiers, i.e., OIDs, consist of three components:
A string containing the system where the database resides (system name),
A string containing the database (“base name”), and
A number containing the local object id within the database.
The full OID is enclosed in ‘<’ and ‘>’ characters, the three name
components are separated by a vertical bar ‘|’.
System and database names obey the naming rules of the underlying operating system and base DBMS, i.e., usually they are made up of lower and upper case characters, underscores, and digits, with digits not as first character. Any additional white space (space, tab, or newline characters) inbetween is assumed to be part of the name, so this should be avoided.
The local OID is an integer number.
Syntax
< systemName | baseName | objectID >
objectID
where systemName and baseName are string literals and objectID is an integerExp.
Example
< acme.com | RASBASE | 42 >
42
4.8.5. String constants¶
A sequence of characters delimited by double quotes is a string.
Syntax
"..."
Example
SELECT encode(coll, "png") FROM coll
4.8.6. Collection Names¶
Collections are named containers for sets of MDD objects (see Linking MDD with Other Data). A collection name is made up of lower and upper case characters, underscores, and digits. Depending on the underlying base DBMS, names may be limited in length, and some systems (rare though) may not distinguish upper and lower case letters.
Operations available on name constants are string equality “=” and
inequality “!=”.
4.9. Spatial Domain Operations¶
4.9.1. One-Dimensional Intervals¶
One-dimensional (1D) intervals describe non-empty, consecutive sets of integer numbers, described by integer-valued lower and upper bound, resp.; negative values are admissible for both bounds. Intervals are specified by indicating lower and upper bound through integer-valued expressions according to the following syntax:
The lower and upper bounds of an interval can be extracted using the functions .lo and .hi.
Syntax
integerExp_1 : integerExp_2
intervalExp.lo
intervalExp.hi
A one-dimensional interval with integerExp_1 as lower bound and integerExp_2 as upper bound is constructed. The lower bound must be less or equal to the upper bound. Lower and upper bound extractors return the integer-valued bounds.
Examples
An interval ranging from -17 up to 245 is written as:
-17 : 245
Conversely, the following expression evaluates to 245; note the parenthesis to enforce the desired evaluation sequence:
(-17 : 245).hi
4.9.2. Multidimensional Intervals¶
Multidimensional intervals (m-intervals) describe areas in space, or better said: point sets. These point sets form rectangular and axis-parallel “cubes” of some dimension. An m-interval’s dimension is given by the number of 1D intervals it needs to be described; the bounds of the “cube” are indicated by the lower and upper bound of the respective 1D interval in each dimension.
From an m-interval, the intervals describing a particular dimension can
be extracted by indexing the m-interval with the number of the desired
dimension using the operator [].
Dimension counting in an m-interval expression runs from left to right, starting with lowest dimension number 0.
Syntax
[ intervalExp_0 , ... , intervalExp_n ]
[ intervalExp_0 , ... , intervalExp_n ] [integerExp ]
An (n+1)-dimensional m-interval with the specified intervalExp_i is built where the first dimension is described by intervalExp_0, etc., until the last dimension described by intervalExp_n.
Example
A 2-dimensional m-interval ranging from -17 to 245 in dimension 1 and from 42 to 227 in dimension 2 can be denoted as
[ -17 : 245, 42 : 227 ]
The expression below evaluates to [42:227].
[ -17 : 245, 42 : 227 ] [1]
...whereas here the result is 42:
[ -17 : 245, 42 : 227 ] [1].lo
4.10. Array Operations¶
As we have seen in the last Section, intervals and m-intervals describe n-dimensional regions in space.
Next, we are going to place information into the regular grid established by the m-intervals so that, at the position of every integer-valued coordinate, a value can be stored. Each such value container addressed by an n-dimensional coordinate will be referred to as a cell. The set of all the cells described by a particular m-interval and with cells over a particular base type, then, forms the array.
As before with intervals, we introduce means to describe arrays through expressions, i.e., to derive new arrays from existing ones. Such operations can change an arrays shape and dimension (sometimes called geometric operations), or the cell values (referred to as value-changing operations), or both. In extreme cases, both array dimension, size, and base type can change completely, for example in the case of a histogram computation.
First, we describe the means to query and manipulate an array’s spatial domain (so-called geometric operations), then we introduce the means to query and manipulate an array’s cell values (value-changing operations).
Note that some operations are restricted in the operand domains they accept, as is common in arithmetics in programming languages; division by zero is a common example. Arithmetic Errors and Other Exception Situations contains information about possible error conditions, how to deal with them, and how to prevent them.
4.10.1. Spatial Domain¶
The m-interval covered by an array is called the array’s spatial domain. Function sdom() allows to retrieve an array’s current spatial domain. The current domain of an array is the minimal axis-parallel bounding box containing all currently defined cells.
As arrays can have variable bounds according to their type definition (see Array types), their spatial domain cannot always be determined from the schema information, but must be recorded individually by the database system. In case of a fixed-size array, this will coincide with the schema information, in case of a variable-size array it delivers the spatial domain to which the array has been set. The operators presented below and in Update allow to change an array’s spatial domain. Notably, a collection defined over variable-size arrays can hold arrays which, at a given moment in time, may differ in the lower and/or upper bounds of their variable dimensions.
Syntax
sdom( mddExp )
Function sdom() evaluates to the current spatial domain of mddExp.
Examples
Consider an image a of collection mr. Elements from this collection are defined as having free bounds, but in practice our collection elements all have spatial domain [0 : 255, 0 : 210]. Then, the following equivalences hold:
sdom(a) = [0 : 255, 0 : 210]
sdom(a)[0] = [0 : 255]
sdom(a)[0].lo = 0
sdom(a)[0].hi = 255
4.10.2. Geometric Operations¶
4.10.2.1. Trimming¶
Reducing the spatial domain of an array while leaving the cell values unchanged is called trimming. Array dimension remains unchanged. Attempting to extend or intersect the array’s spatial domain will lead to an error; use the extend function in this case.
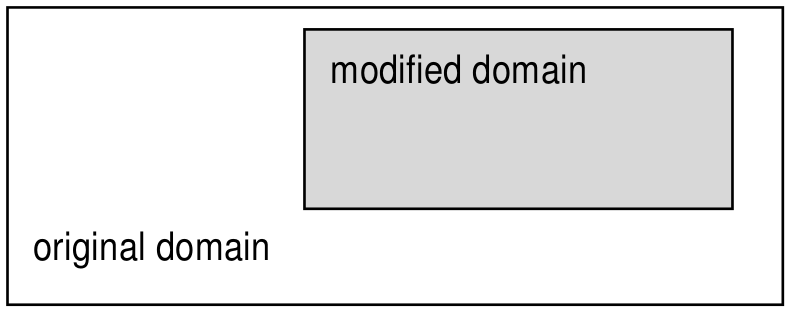
Figure 4.6 Spatial domain modification through trimming (2-D example)¶
Syntax
mddExp [ mintervalExp ]
Examples
The following query returns cutouts from the area [120: 160 , 55 : 75]
of all images in collection mr (see Figure 4.7).
select mr[ 120:160, 55:75 ]
from mr

Figure 4.7 Trimming result¶
4.10.2.2. Section¶
A section allows to extract lower-dimensional layers (“slices”) from an array.
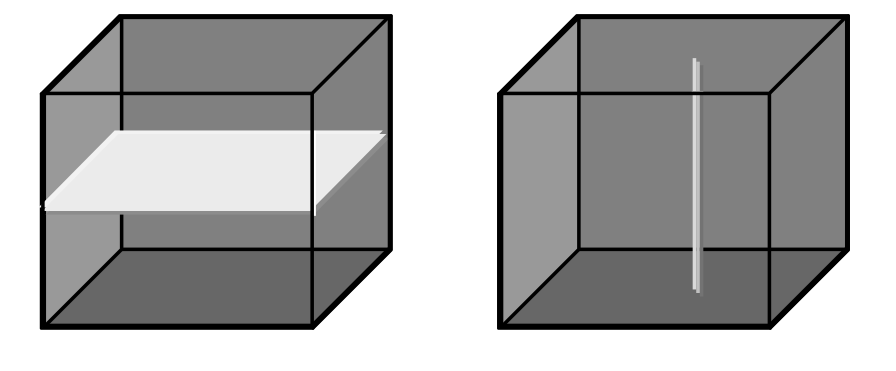
Figure 4.8 Single and double section through 3-D array, yielding 2-D and 1-D sections.¶
A section is accomplished through a trim expression by indicating the slicing position rather than a selection interval. A section can be made in any dimension within a trim expression. Each section reduces the dimension by one.
Like with trimming, a section must be within the spatial domain of the array, otherwise an error indicating that the subset domain extends outside of the array spatial domain will be thrown.
Syntax
mddExp [ integerExp_0 , ... , integerExp_n ]
This makes sections through mddExp at positions integerExp_i for each dimension i.
Example
The following query produces a 2-D section in the 2nd dimension of a 3-D cube:
select Images3D[ 0:256, 10, 0:256 ]
from Images3D
Note
If a section is done in every dimension of an array, the result is one single cell. This special case resembles array element access in programming languages, e.g., C/C++. However, in rasql the result still is an array, namely one with zero dimensions and exactly one element.
Example
The following query delivers a set of 0-D arrays containing single pixels, namely the ones with coordinate [100,150]:
select mr[ 100, 150 ]
from mr
4.10.2.3. Trim Wildcard Operator “*”¶
An asterisk “*” can be used as a shorthand for an sdom() invocation in a trim expression; the following phrases all are equivalent:
a [ *:*, *:* ] = a [ sdom(a)[0] , sdom(a)[1] ]
= a [ sdom(a)[0].lo : sdom(a)[0].hi ,
sdom(a)[1].lo : sdom(a)[1].hi ]
An asterisk “*” can appear at any lower or upper bound position within a trim expression denoting the current spatial domain boundary. A trim expression can contain an arbitrary number of such wildcards. Note, however, that an asterisk cannot be used for specifying a section.
Example
The following are valid applications of the asterisk operator:
select mr[ 50:*, *:200 ]
from mr
select mr[ *:*, 10:150 ]
from mr
The next is illegal because it attempts to use an asterisk in a section:
select mr[ *, 100:200 ] -- illegal "*" usage in dimension 0
from mr
Note
It is well possible (and often recommended) to use an array’s spatial domain or part of it for query formulation; this makes the query more general and, hence, allows to establish query libraries. The following query cuts away the rightmost pixel line from the images:
select mr[ *:*, *:sdom(mr)[1].hi - 1 ] -- good, portable
from mr
In the next example, conversely, trim bounds are written explicitly; this query’s trim expression, therefore, cannot be used with any other array type.
select mr[ 0:767, 0:1023 ] -- bad, not portable
from mr
One might get the idea that the last query evaluates faster. This, however, is not the case; the server’s intelligent query engine makes the first version execute at just the same speed.
4.10.2.4. Positionally-independent Subsetting¶
Rasdaman supports positionally-independent subsetting like in WCPS and SQL/MDA, where for each trim/slice the axis name is indicated as well, e.g.
select mr2[d0(0:100), d1(50)] from mr2
The axis names give a reference to the addressed axes, so the order doesn’t matter anymore. This is equivalent:
select mr2[d1(50), d0(0:100)] from mr2
Furthermore, not all axes have to be specified. Any axes which are not specified default to “:”. For example:
select mr2[d1(50)] from mr2
=
select mr2[d0(*:*), d1(50)] from mr2
The two subset formats cannot be mixed, e.g. this is an error:
select mr2[d0(0:100), 50] from mr2
4.10.2.5. Shifting a Spatial Domain¶
Built-in function shift() transposes an array: its spatial domain remains unchanged in shape, but all cell contents simultaneously are moved to another location in n-dimensional space. Cell values themselves remain unchanged.
Syntax
shift( mddExp , pointExp )
The function accepts an mddExp and a pointExp and returns an array whose spatial domain is shifted by vector pointExp.
Example
The following expression evaluates to an array with spatial domain
[3:13, 4:24]. Containing the same values as the original array a.
shift( a[ 0:10, 0:20 ], [ 3, 4 ] )
4.10.2.6. Extending a Spatial Domain¶
Function extend() enlarges a given MDD with the domain specified. The domain for extending must, for every boundary element, be at least as large as the MDD’s domain boundary. The new MDD contains 0 values in the extended part of its domain and the MDD’s original cell values within the MDD’s domain.
Syntax
extend( mddExp , mintervalExp )
The function accepts an mddExp and a mintervalExp and returns an array whose spatial domain is extended to the new domain specified by mintervalExp. The result MDD has the same cell type as the input MDD.
Precondition:
sdom( mddExp ) contained in mintervalExp
Example
Assuming that MDD a has a spatial domain of [0:50, 0:25], the following
expression evaluates to an array with spatial domain [-100:100, -50:50],
a‘s values in the subdomain [0:50, 0:25], and 0 values at the
remaining cell positions.
extend( a, [-100:100, -50:50] )
4.10.2.7. Geographic projection¶
4.10.2.7.1. Overview¶
“A map projection is any method of representing the surface of a sphere or other three-dimensional body on a plane. Map projections are necessary for creating maps. All map projections distort the surface in some fashion. Depending on the purpose of the map, some distortions are acceptable and others are not; therefore different map projections exist in order to preserve some properties of the sphere-like body at the expense of other properties.” (Wikipedia)
Each coordinate tieing a geographic object, map, or pixel to some position on earth (or some other celestial object, for that matter) is valid only in conjunction with the Coordinate Reference System (CRS) in which it is expressed. For 2-D Earth CRSs, a set of CRSs and their identifiers is normatively defined by the OGP Geomatics Committee, formed in 2005 by the absorption into OGP of the now-defunct European Petroleum Survey Group (EPSG). By way of tradition, however, this set of CRS definitions still is known as “EPSG”, and the CRS identifiers as “EPSG codes”. For example, EPSG:4326 references the well-known WGS84 CRS.
4.10.2.7.2. The project() function¶
Assume an MDD object M and two CRS identifiers C1 and C2 such as
“EPSG:4326”. The project() function establishes an output MDD, with same
dimension as M, whose contents is given by projecting M from CRS C1
into CRS C2.
The project() function comes in several variants based on the provided
input arguments
(1) project( mddExpr, boundsIn, crsIn, crsOut )
(2) project( mddExpr, boundsIn, crsIn, crsOut, resampleAlg )
(3) project( mddExpr, boundsIn, crsIn, boundsOut, crsOut,
widthOut, heightOut )
(4) project( mddExpr, boundsIn, crsIn, boundsOut, crsOut,
widthOut, heightOut, resampleAlg, errThreshold )
(5) project( mddExpr, boundsIn, crsIn, boundsOut, crsOut,
xres, yres)
(6) project( mddExpr, boundsIn, crsIn, boundsOut, crsOut,
xres, yres, resampleAlg, errThreshold )
where
mddExpr- MDD object to be reprojected.boundsIn- geographic bounding box given as a string of comma-separated floating-point values of the format:"xmin, ymin, xmax, ymax".crsIn- geographic CRS as a string. Internally, theproject()function is mapped to GDAL; hence, it accepts the same CRS formats as GDAL:Well Known Text (as per GDAL)
“EPSG:n”
“EPSGA:n”
“AUTO:proj_id,unit_id,lon0,lat0” indicating OGC WMS auto projections
“
urn:ogc:def:crs:EPSG::n” indicating OGC URNs (deprecated by OGC)PROJ.4 definitions
well known names, such as NAD27, NAD83, WGS84 or WGS72.
WKT in ESRI format, prefixed with “ESRI::”
“IGNF:xxx” and “+init=IGNF:xxx”, etc.
Since recently (v1.10), GDAL also supports OGC CRS URLs, OGC’s preferred way of identifying CRSs.
boundsOut- geographic bounding box of the projected output, given in the same format asboundsIn. This can be “smaller” than the input bounding box, in which case the input will be cropped.crsOut- geographic CRS of the result, in same format ascrsIn.widthOut,heightOut- integer grid extents of the result; the result will be accordingly scaled to fit in these extents.xres,yres- axis resolution in target georeferenced units.
resampleAlg- resampling algorithm to use, equivalent to the ones in GDAL:- near
Nearest neighbour (default, fastest algorithm, worst interpolation quality).
- bilinear
Bilinear resampling (2x2 kernel).
- cubic
Cubic convolution approximation (4x4 kernel).
- cubicspline
Cubic B-spline approximation (4x4 kernel).
- lanczos
Lanczos windowed sinc (6x6 kernel).
- average
Average of all non-NODATA contributing pixels. (GDAL >= 1.10.0)
- mode
Selects the value which appears most often of all the sampled points. (GDAL >= 1.10.0)
- max
Selects the maximum value from all non-NODATA contributing pixels. (GDAL >= 2.0.0)
- min
Selects the minimum value from all non-NODATA contributing pixels. (GDAL >= 2.0.0)
- med
Selects the median value of all non-NODATA contributing pixels. (GDAL >= 2.0.0)
- q1
Selects the first quartile value of all non-NODATA contributing pixels. (GDAL >= 2.0.0)
- q3
Selects the third quartile value of all non-NODATA contributing pixels. (GDAL >= 2.0.0)
errThreshold- error threshold for transformation approximation (in pixel units - defaults to 0.125).
Example
The following expression projects the MDD worldMap with bounding box
“-180, -90, 180, 90” in CRS EPSG 4326, into EPSG 54030:
project( worldMap, "-180, -90, 180, 90", "EPSG:4326", "EPSG:54030" )
The next example reprojects a subset of MDD Formosat with geographic
bbox “265725, 2544015, 341595, 2617695” in EPSG 32651, to bbox
“120.630936455 23.5842129067 120.77553782 23.721772322” in EPSG 4326 fit into
a 256 x 256 pixels area. The resampling algorithm is set to bicubic, and the
pixel error threshold is 0.1.
project( Formosat[ 0:2528, 0:2456 ],
"265725, 2544015, 341595, 2617695", "EPSG:32651",
"120.630936455 23.5842129067 120.77553782 23.721772322", "EPSG:4326",
256, 256, cubic, 0.1 )
Limitations
Only 2-D arrays are supported. For multiband arrays, all bands must be of the same cell type.
4.10.2.7.3. Notes¶
Reprojection implies resampling of the cell values into a new grid, hence usually they will change.
As for the resampling process typically a larger area is required than the reprojected data area itself, it is advisable to project an area smaller than the total domain of the MDD.
Per se, rasdaman is a domain-agnostic Array DBMS and, hence, does not
know about CRSs; specific geo semantics is added by rasdaman’s petascope
layer. However, for the sake of performance, the
reprojection capability – which in geo service practice is immensely important
– is pushed down into rasdaman, rather than doing reprojection in
petascope’s Java code. To this end, the project() function provides rasdaman
with enough information to perform a reprojection, however, without
“knowing” anything in particular about geographic coordinates and CRSs.
One consequence is that there is no check whether this lat/long project is
applied to the proper axis of an array; it is up to the application (usually:
petascope) to handle axis semantics.
One consequence is that there is no check whether this lat/long project is applied to the proper axis of an array; it is up to the application (usually: petascope) to handle axis semantics.
4.10.3. Clipping Operations¶
Clipping is a general operation covering polygon clipping, linestring
selection, polytope clipping, curtain queries, and corridor queries. Presently,
all operations are available in rasdaman via the clip function.
Further examples of clipping can be found in the systemtest for clipping.
4.10.3.1. Polygons¶
4.10.3.1.1. Syntax¶
select clip( c, polygon(( list of WKT points )) )
from coll as c
The input consists of an MDD expression and a list of WKT points, which determines the set of vertices of the polygon. Polygons are assumed to be closed with positive area, so the first vertex need not be repeated at the end, but there is no problem if it is. The algorithms used support polygons with self-intersection and vertex re-visitation.
Polygons may have interiors defined, such as
polygon( ( 0 0, 9 0, 9 9, 0 9, 0 0),
( 3 3, 7 3, 7 7, 3 7, 3 3 ) )
which would describe the annular region of the box [0:9,0:9] with the
interior box [3:7,3:7] removed. In this case, the interior polygons (there
may be many, as it forms a list) must not intersect the exterior polygon.
4.10.3.2. Multipolygons¶
4.10.3.2.1. Syntax¶
select clip( c, multipolygon((( list of WKT points )),(( list of WKT points ))...) )
from coll as c
The input consists of an MDD expression and a list of polygons defined by list of WKT points. The assumptions about polygons are same as the ones for Polygon.
4.10.3.2.2. Return type¶
The output of a polygon query is a new array with dimensions corresponding to the bounding box of the polygon vertices, and further restricted to the collection’s spatial domain. In case of Multipolygon, the new array have dimensions corresponding to closure of bounding boxes of every individual polygon, which domain intersects the collection’s spatial domain. The data in the array consists of null values where cells lie outside the polygon (or 0 values if no null values are associated with the array) and otherwise consists of the data in the collection where the corresponding cells lie inside the polygon. This could change the null values stored outside the polygon from one null value to another null value, in case a range of null values is used. By default, the first available null value will be utilized for the complement of the polygon.
An illustrative example of a polygon clipping is the right triangle with
vertices located at (0,0,0), (0,10,0) and (0,10,10), which can be
selected via the following query:
select clip( c, polygon((0 0 0, 0 10 0, 0 10 10)) )
from coll as c
4.10.3.2.3. Oblique polygons with subspacing¶
In case all the points in a polygon are coplanar, in some MDD object d of
higher dimension than 2, users can first perform a subspace operation on d
which selects the 2-D oblique subspace of d containing the polygon. For
example, if the polygon is the triangle polygon((0 0 0, 1 1 1, 0 1 1, 0 0 0)),
this triangle can be selected via the following query:
select clip( subspace(d, (0 0 0, 1 1 1, 0 1 1) ),
polygon(( 0 0, 1 1 , 0 1 , 0 0)) )
from coll as d
where the result of subspace(d) is used as the domain of the polygon. For
more information look in Subspace Queries.
4.10.3.3. Linestrings¶
4.10.3.3.1. Syntax¶
select clip( c, linestring( list of WKT points ) ) [ with coordinates ]
from coll as c
The input parameter c refers to an MDD expression of dimension equal to the
dimension of the points in the list of WKT points. The list of WKT points
consists of parameters such as linestring(0 0, 19 -3, 19 -21), which would
describe the 3 endpoints of 2 line segments sharing an endpoint at 19 -3, in
this case.
4.10.3.3.2. Return type¶
The output consists of a 1-D MDD object consisting of the points selected along
the path drawn out by the linestring. The points are selected using a Bresenham
Line Drawing algorithm which passes through the spatial domain in the MDD
expression c, and selects values from the stored object. In case the
linestring spends some time outside the spatial domain of c, the first
null value will be used to fill the result of the linestring, just as in polygon
clipping.
When with coordinates is specified, in addition to the original cell values
the coordinate values are also added to the result MDD. The result cell type for
clipped MDD of dimension N will be composite of the following form:
If the original cell type
elemtypeis non-composite:{ long d1, ..., long dN, elemtype value }
Otherwise, if the original cell type is composite of
Mbands:{ long d1, ..., long dN, elemtype1 elemname1, ..., elemetypeM elemnameM }
4.10.3.3.3. Example¶
Select a Linestring from rgb data with coordinates. First two values of each
cell in the result are the x/y coordinates, with following values (three in this
case for RGB data) are the cell values of the clip operation to which
with coordinates is applied.
select encode(
clip( c, linestring(0 19, 19 24, 12 17) ) with coordinates, "json")
from rgb as c
Result:
["0 19 119 208 248","1 19 119 208 248","2 20 119 208 248", ...]
The same query without specifying with coordinates:
select encode(
clip( c, linestring(0 19, 19 24, 12 17) ), "json")
from rgb as c
results in
["119 208 248","119 208 248","119 208 248", ...]
4.10.3.4. Curtains¶
4.10.3.4.1. Syntax¶
select clip( c, curtain( projection(dimension pair),
polygon(( ... )) ) )
from coll as c
and
select clip( c, curtain( projection(dimension list),
linestring( ... ) ) )
from coll as c
The input in both variants consists of a dimension list corresponding to the
dimensions in which the geometric object, either the polygon or the linestring,
is defined. The geometry object is defined as per the above descriptions;
however, the following caveat applies: the spatial domain of the mdd expression
is projected along the projection dimensions in the projection(dimension
list). For a polygon clipping, which is 2-D, the dimension list is a pair of
values such as projection(0, 2) which would define a polygon in the axial
dimensions of 0 and 2 of the MDD expression c. For instance, if the spatial
domain of c is [0:99,0:199,0:255], then this would mean the domain upon
which the polygon is defined would be [0:99,0:255].
4.10.3.4.2. Return type¶
The output consists of a polygon clipping at every slice of the spatial domain
of c. For instance, if the projection dimensions of (0, 2) are used for
the same spatial domain of c above, then a polygon clipping is performed at
every slice of c of the form [0:99,x,0:255] and appended to the result
MDD object, where there is a slice for each value of x in [0:199].
4.10.3.5. Corridors¶
4.10.3.5.1. Syntax¶
select clip( c, corridor( projection(dimension pair),
linestring( ... ),
polygon(( ... )) ) )
from coll as c
and
select clip( c, corridor( projection(dimension pair),
linestring( ... ),
polygon(( ... )),
discrete ) )
from coll as c
The input consists of a dimension list corresponding to the dimensions in which the geometric object, in this case a polygon, is defined. The linestring specifies the path along which this geometric object is integrated. One slice is sampled at every point, and at least the first point of the linestring should be contained within the polygon to ensure a meaningful result (an error is thrown in case it is not). There is an optional discrete flag which modifies the output by skipping the extrapolation of the linestring data to interior points.
4.10.3.5.2. Return type¶
The output consists of a polygon clipping at every slice of the spatial domain
of c translated along the points in the linestring, where the first axis of
the result is indexed by the linestring points and the latter axes are indexed
by the mask dimensions (in this case, the convex hull of the polygon). The
projection dimensions are otherwise handled as in curtains; it is the spatial
offsets given by the linestring coordinates which impact the changes in the
result. In the case where the discrete parameter was utilized, the output is
indexed by the number of points in the linestring description in the query and
not by the extrapolated linestring, which uses a Bresenham algorithm to find
the grid points in between.
4.10.3.6. Subspace Queries¶
Here we cover the details of subspace queries in rasdaman. Much like slicing via a query such as
select c[0:9,1,0:9] from collection as c
the subspace query parameter allows users to extract a lower-dimensional dataset from an existing collection. It is capable of everything that a slicing query is capable of, and more. The limitation of slicing is that the selected data must lie either parallel or perpendicular to existing axes; however, with subspacing, users can arbitrarily rotate the axes of interest to select data in an oblique fashion. This control is exercised by defining an affine subspace from a list of vertices lying in the datacube. Rasdaman takes these points and finds the unique lowest-dimensional affine subspace containing them, and outputs the data closest to this slice, contained in the bounding box of the given points, into the resulting array.
Structure of the query:
select clip( c, subspace(list of WKT points) )
from coll as c
We can illustrate the usage with an example of two queries which are identical in output:
select clip( c, subspace(0 0 0, 1 0 0, 0 0 1) ) from coll as c
select c[0:1,0,0:1] from coll as c
This example will result in 1D array of sdom [0:99]:
select clip( c, subspace(19 0, 0 99) ) from test_rgb as c
This example will result in a a 2D array of sdom [0:7,0:19]:
select clip( c, subspace(0 0 0, 0 19 0, 7 0 7) )
from test_grey3d as c
and it will consist of the best integer lattice points reachable by the vectors
(1,0,1) and (0,1,0) within the bounding box domain of [0:7,0:19,0:7]
in test_grey3d.
Generally speaking, rasdaman uses the 1st point as a basepoint for an affine
subspace containing all given points, constructs a system of equations to
determine whether or not a point is in that subspace or not, and then searches
the bounding box of the given points for solutions to the projection operator
which maps [0:7,0:19,0:7] to [0:7,0:19]. The result dimensions are
chosen such that each search yields a unique real solution, and then rasdaman
rounds to the nearest integer cell before adding the value stored in that cell
to the result object.
Some mathematical edge cases:
Because of arithmetic on affine subspaces, the following two queries are fundamentally identical to rasdaman:
select clip( c, subspace(0 0 0, 1 1 0, 0 1 0) )
from test_grey3d as c
select clip( c, subspace(0 0 0, 1 0 0, 0 1 0) )
from test_grey3d as c
Rasdaman’s convention is to use the first point as the translation point, and constructs the vectors generating the subspace from the differences. There is no particular reason not to use another point in the WKT list; however, knowing this, users should be aware that affine subspaces differ slightly from vector subspaces in that the following two queries differ:
select clip( c, subspace(10 10 10, 0 0 10, 10 0 10) )
from test_grey3d as c
select clip( c, subspace(0 0 0, 10 10 0, 0 10 0) )
from test_grey3d as c
The two queries have the same result domains of [0:10,0:10], and the projection
for both lie on the first 2 coordinate axes since the 3rd coordinate remains
constant; however, the data selections differ because the subspaces generated by
these differ, even though the generating vectors of (1 1 0) and (0 1 0)
are the same.
Even though the bounding box where one searches for solutions is the same
between these two queries, there is no way to reach the origin with the vectors
(1 1 0) and (0 1 0) starting at the base point of (10 10 10) because
neither vector can impact the 3rd coordinate value of 10; similarly, starting at
(0 0 0) must leave the third coordinate fixed at 0. There is nothing special
about choosing the first coordinate as our base point – the numbers might
change, but the resulting data selections in both queries would remain constant.
The following two queries generate the same subspace, but the latter has a larger output domain:
select clip( c, subspace(0 0 0, 1 1 0, 0 1 0) )
from test_grey3d as c
select clip( c, subspace(0 0 0, 1 1 0, 0 1 0, 0 0 0, 1 2 0) )
from test_grey3d as c
As much redundancy as possible is annihilated during a preprocessing stage which uses a Gram-Schmidt procedure to excise extraneous data imported during query time, and with this algorithm, rasdaman is able to determine the correct dimension of the output domain.
Some algorithmic caveats:
The complexity of searching for a solution for each result cell is related to
the codimension of the affine subspace, and not the dimension of the affine
subspace itself. In fact, if k is the difference between the dimension of the
collection array and the dimension of the result array, then each cell is
determined in O(k^2) time. Preprocessing happens once for the entire query,
and occurs in O(k^3) time. There is one exception to the codimensionality
considerations: a 1-D affine subspace (also known as a line segment) is selected
using a multidimensional generalization of the Bresenham Line Algorithm, and so
the results are determined in O(n) time, where n is the dimension of the
collection.
Tip: If you want a slice which is parallel to axes, then you are better off using the classic slicing style of:
select c[0:19,0:7,0] from collection as c
as the memory offset computations are performed much more efficiently.
4.10.4. Induced Operations¶
Induced operations allow to simultaneously apply a function originally working on a single cell value to all cells of an MDD. The result MDD has the same spatial domain, but can change its base type.
Examples
img.green + 5 c
This expression selects component named “green” from an RGB image and adds 5 (of type char, i.e., 8 bit) to every pixel.
img1 + img2
This performs pixelwise addition of two images (which must be of equal spatial domain).
Induction and structs
Whenever induced operations are applied to a composite cell structure (“structs” in C/C++), then the induced operation is executed on every structure component. If some cell structure component turns out to be of an incompatible type, then the operation as a whole aborts with an error.
For example, a constant can be added simultaneously to all components of an RGB image:
select rgb + 5
from rgb
Induction and complex
Complex numbers, which actually form a composite type supported as a base type, can be accessed with the record component names re and im for the real and the imaginary part, resp.
Example
The first expression below extracts the real component, the second one the imaginary part from a complex number c:
c.re
c.im
4.10.4.1. Unary Induction¶
Unary induction means that only one array operand is involved in the expression. Two situations can occur: Either the operation is unary by nature (such as boolean not); then, this operation is applied to each array cell. Or the induce operation combines a single value (scalar) with the array; then, the contents of each cell is combined with the scalar value.
A special case, syntactically, is the struct/complex component selection (see next subsection).
In any case, sequence of iteration through the array for cell inspection is chosen by the database server (which heavily uses reordering for query optimisation) and not known to the user.
Syntax
unaryOp mddExp
mddExp binaryOp scalarExp
scalarExp binaryOp mddExp
Example
The red images of collection rgb with all pixel values multiplied by 2:
select rgb.red * 2c
from rgb
Note that the constant is marked as being of type char so that the result type
is minimized (short). Omitting the “c” would lead to an addition of long
integer and char, resulting in long integer with 32 bit per pixel. Although
pixel values obviously are the same in both cases, the second alternative
requires twice the memory space. For more details visit the
Type Coercion Rules section.
4.10.4.2. Struct Component Selection¶
Component selection from a composite value is done with the dot operator well-known from programming languages. The argument can either be a number (starting with 0) or the struct element name. Both statements of the following example would select the green plane of the sample RGB image.
This is a special case of a unary induced operator.
Syntax
mddExp.attrName
mddExp.intExp
Examples
select rgb.green
from rgb
select rgb.1
from rgb

Figure 4.9 RGB image and green component¶
Note
Aside of operations involving base types such as integer and boolean, combination of complex base types (structs) with scalar values are supported. In this case, the operation is applied to each element of the structure in turn.
Examples
The following expression reduces contrast of a color image in its red, green, and blue channel simultaneously:
select rgb / 2c
from rgb
An advanced example is to use image properties for masking areas in this image. In the query below, this is done by searching pixels which are “sufficiently green” by imposing a lower bound on the green intensity and upper bounds on the red and blue intensity. The resulting boolean matrix is multiplied with the original image (i.e., componentwise with the red, green, and blue pixel component); the final image, then, shows the original pixel value where green prevails and is {0,0,0} (i.e., black) otherwise (Figure 4.10)
select rgb * ( (rgb.green > 130c) and
(rgb.red < 110c) and
(rgb.blue < 140c) )
from rgb

Figure 4.10 Suppressing “non-green” areas¶
Note
This mixing of boolean and integer is possible because the usual C/C++ interpretation of true as 1 and false as 0 is supported by rasql.
4.10.4.3. Binary Induction¶
Binary induction means that two arrays are combined.
Syntax
mddExp binaryOp mddExp
Example
The difference between the images in the mr collection and the image in
the mr2 collection:
select mr - mr2
from mr, mr2
Note
Two cases have to be distinguished:
Both left hand array expression and right hand array expression operate on the same array, for example:
select rgb.red - rgb.green from rgb
In this case, the expression is evaluated by combining, for each coordinate position, the respective cell values from the left hand and right hand side.
Left hand array expression and right hand array expression operate on different arrays, for example:
select mr - mr2 from mr, mr2
This situation specifies a cross product between the two collections involved. During evaluation, each array from the first collection is combined with each member of the second collection. Every such pair of arrays then is processed as described above.
Obviously the second case can become computationally very expensive, depending on the size of the collections involved - if the two collections contain n and m members, resp., then n*m combinations have to be evaluated.
4.10.4.4. Case statement¶
The rasdaman case statement serves to model n-fold case distinctions based on the SQL92 CASE statement which essentially represents a list of IF-THEN statements evaluated sequentially until either a condition fires and delivers the corresponding result or the (mandatory) ELSE alternative is returned.
In the simplest form, the case statement looks at a variable and compares it to different alternatives for finding out what to deliver. The more involved version allows general predicates in the condition.
This functionality is implemented in rasdaman on both scalars (where it resembles SQL) and on MDD objects (where it establishes an induced operation). Due to the construction of the rasql syntax, the distinction between scalar and induced operations is not reflected explicitly in the syntax, making query writing simpler.
Syntax
Variable-based variant:
case generalExp when scalarExp then generalExp ... else generalExp end
All generalExps must be of a compatible type.
Expression-based variant:
case when booleanExp then generalExp ... else generalExp end
All generalExp’s must evaluate to a compatible type.
Example
Traffic light classification of an array object can be done as follows.
select
case
when mr > 150 then { 255c, 0c, 0c }
when mr > 100 then { 0c, 255c, 0c }
else { 0c, 0c, 255c }
end
from mr
This is equivalent to the following query; note that this query is less efficient due to the increased number of operations to be evaluated, the expensive multiplications, etc:
select
(mr > 150) { 255c, 0c, 0c }
+ (mr <= 150 and mr > 100) { 0c, 255c, 0c }
+ (mr <= 100) { 0c, 0c, 255c }
from mr
Restrictions
In the current version, all MDD objects participating in a case statement must have the same tiling. Note that this limitation can often be overcome by factoring divergingly tiled arrays out of a query, or by resorting to the query equivalent in the above example using multiplication and addition.
4.10.4.5. Induction: All Operations¶
Below is a complete listing of all cell level operations that can be induced, both unary and binary. Supported operand types and rules for deriving the result types for each operation are specified in Type Coercion Rules.
- +, -, *, /
For each cell within some MDD value (or evaluated MDD expression), add it with the corresponding cell of the second MDD parameter. For example, this code adds two (equally sized) images:
img1 + img2
- div, mod
In contrast to the previous operators, div and mod are binary functions. The difference of
divto/is that in the case of integer inputs,divresults in integer result, and hence must check for division with 0, in which case an error would be thrown. The behaviour ofmodis the same. Example usage:div(a, b) mod(a, b)
- pow, power
The power function can be written as
poworpower. The signature is:pow( base, exp )
where base and is an MDD or scalar, and exp is likewise an MDD or scalar.
- =, <, >, <=, >=, !=
For two MDD values (or evaluated MDD expressions), compare for each coordinate the corresponding cells to obtain the Boolean result indicated by the operation.
These comparison operators work on all atomic cell types.
On composite cells, only
=and!=are supported; both operands must have a compatible cell structure. In this case, the comparison result is the conjunction (“and” connection) of the pairwise comparison of all cell components.- and, or, xor, is, not
For each cell within some Boolean MDD (or evaluated MDD expression), combine it with the second MDD argument using the logical operation
and,or, orxor. Theisoperation is equivalent to=(see below). The signature of the binary induced operation isis, and, or, xor: mddExp, intExp -> mddExp
Unary function
notnegates each cell value in the MDD.- min, max
For two MDD values (or evaluated MDD expressions), take the minimum / maximum for each pair of corresponding cell values in the MDDs.
Example:
a min b
For struct valued MDD values, struct components in the MDD operands must be pairwise compatible; comparison is done in lexicographic order with the first struct component being most significant and the last component being least significant.
- overlay
The overlay operator allows to combine two equally sized MDDs by placing the second one “on top” of the first one, informally speaking. Formally, overlaying is done in the following way:
wherever the second operand’s cell value is not zero and not null, the result value will be this value.
wherever the second operand’s cell value is zero or null, the first argument’s cell value will be taken.
This way stacking of layers can be accomplished, e.g., in geographic applications. Consider the following example:
ortho overlay tk.water overlay tk.streets
When displayed the resulting image will have streets on top, followed by water, and at the bottom there is the ortho photo.
Strictly speaking, the overlay operator is not atomic. Expression
a overlay b
is equivalent to
(b is not null) * b + (b is null) * a
However, on the server the overlay operator is executed more efficiently than the above expression.
- bit(mdd, pos)
For each cell within MDD value (or evaluated MDD expression) mdd, take the bit with nonnegative position number pos and put it as a Boolean value into a byte. Position counting starts with 0 and runs from least to most significant bit. The bit operation signature is
bit: mddExp, intExp -> mddExp
In C/C++ style,
bit(mdd, pos)is equivalent tomdd >> pos & 1.
- Arithmetic, trigonometric, and exponential functions
The following advanced arithmetic functions are available with the obvious meaning, each of them accepting an MDD object (except
arctan2which expects two floating-point operands of the same type):abs() sqrt() exp() log() ln() sin() cos() tan() sinh() cosh() tanh() arcsin() arccos() arctan() arctan2() ceil() floor() round()
Exceptions
Generally, on domain error or other invalid cell values these functions will not throw an error, but result in NaN or similar according to IEEE floating-point arithmetic. Internally the rasdaman implementation calls the corresponding C++ functions, so the C++ documentation applies.
The
ceil,floor, androundfunctions are applicable only on floating-point arguments and have no effect on other atomic types (e.g. char). On multi-band arguments with bands of mixed floating-point and other base types, these function are not applicable and throw an error.- cast
Sometimes the desired ultimate scalar type or MDD cell type is different from what the MDD expression would suggest. To this end, the result type can be enforced explicitly through the cast operator.
The syntax is:
(newType) generalExp
where newType is the desired result type of expression generalExp.
Like in programming languages, the cast operator converts the result to the desired type if this is possible at all. For example, the following scalar expression, without cast, would return a double precision float value; the cast makes it a single precision value:
(float) avg_cells( mr )
Both scalar values and MDD can be cast; in the latter case, the cast operator is applied to each cell of the MDD yielding an array over the indicated type.
The cast operator also works properly on composite cell structures. In such a case, the cast type is applied to every component of the cell. For example, the following expression converts the pixel type of an (3x8 bit) RGB image to an image where each cell is a structure with three long components:
(long) rgb
Obviously in the result structure all components will bear the same type. In addition, the target type can be a user-defined composite type, e.g. the following will cast the operand to {1c, 2c, 3c}:
(RGBPixel) {1c, 2l, 3.0}
Casting from larger to smaller integer type
If the new type is smaller than the value’s type, i.e. not all values can be represented by it, then standard C++ casting will typically lead to strange results due to wrap around for unsigned and implementation-defined behavior for a signed types. For example, casting int 1234 to char in C++ will result in 210, while the possible range would be 0 - 255.
Rasdaman implements a more reasonable cast behavior in this case: if the value is larger than the maximum value representable by the new type, then the result is the maximum value (e.g. 255 in the previous example); analogously, if the value is smaller than the minimum possible value, then the result is the minimum value.
This is implemented only on integer types and entails a small performance penalty in comparison to raw C++ as up to two comparisons per cell (with the maximum and minimum) are necessary when casting.
Restrictions
On base type complex, only the following operations are available right now:
+ - * /
4.10.5. Scaling¶
Shorthand functions are available to scale multidimensional objects. They receive an array as parameter, plus a scale indicator. In the most common case, the scaling factor is an integer or float number. This factor then is applied to all dimensions homogeneously. For a scaling with individual factors for each dimension, a scaling vector can be supplied which, for each dimension, contains the resp. scale factor. Alternatively, a target domain can be specified to which the object gets scaled.
Syntax
scale( mddExp, intExp )
scale( mddExp, floatExp )
scale( mddExp, intVector )
scale( mddExp, mintervalExp )
Examples
The following example returns all images of collection mr where each
image has been scaled down by a factor of 2.
select scale( mr, 0.5 )
from mr
Next, mr images are enlarged by 4 in the first dimension and 3 in the second dimension:
select scale( mr, [ 4, 3 ] )
from mr
In the final example, mr images are scaled to obtain 100x100 thumbnails (note that this can break aspect ratio):
select scale( mr, [ 0:99, 0:99 ] )
from mr
Note
Function scale() breaks tile streaming, it needs to load all tiles
affected into server main memory. In other words, the source argument of
the function must fit into server main memory. Consequently, it is not
advisable to use this function on very large items.
Note
Currently only nearest neighbour interpolation is supported for scaling. It uses floor for rounding to integer coordinates when finding the nearest neighbour. So it has same behavior as OpenCV, for example, as explained in this blog post.
4.10.6. Concatenation¶
Concatenation of two arrays “glues” together arrays by lining them up along an axis.
This can be achieved with a shorthand function, concat, which for
convenience is implemented as an n-ary operator accepting an unlimited number
of arrays of the same base type. The operator takes the input arrays, lines
them up along the concatenation dimension specified in the request, and outputs
one result array. To this end, each input array from the second one on is
shifted to the origin of the first one, except along the concatenation
dimension where it’s shifted so that the lower bound of the current array is
right after the upper bound of the previous array.
The resulting array’s dimensionality is equal to the input array dimensionality.
The resulting array extent is the sum of all extents along the concatenation dimension, and the extent of the input arrays in all other dimensions; the origin is same as the origin of the first input array.
The resulting array cell type is same as the cell types of the input arrays.
Constraints
All participating arrays must have the same number of dimensions.
All participating arrays must have identical extents in all dimensions, except the dimension along which concatenation is performed.
Input arrays must have the same cell types, i.e. concatenating a char and float arrays is not possible and requires explicit casting to a common type.
Syntax
concat mddExp with mddExp ... with mddExp along integer
Examples
The following query returns the concatenation of all images of collection mr with themselves along the first dimension (Figure 4.11).
select concat mr with mr along 0
from mr
Figure 4.11 Query result of single concatenation¶
The next example returns a 2x2 arrangement of images (Figure 4.12):
select concat (concat mr with mr along 0)
with (concat mr with mr along 0)
along 1
from mr
Figure 4.12 Query result of multiple concatenation¶
4.10.7. Condensers¶
Frequently summary information of some kind is required about some array, such as sum or average of cell values. To accomplish this, rasql provides the concept of condensers.
A condense operation (or short: condenser) takes an array and summarizes its values using a summarization function, either to a scalar value (e.g. computing the sum of all its cells), or to another array (e.g. summarizing a 3-D cube into a 2-D image by adding all the horizontal slices that the cube is composed of).
A number of condensers is provided as rasql built-in functions.
For numeric arrays,
add_cells()delivers the sum andavg_cells()the average of all cell values. Operatorsmin_cells()andmax_cells()return the minimum and maximum, resp., of all cell values in the argument array.stddev_pop,stddev_samp,var_pop, andvar_sampallow to calculate the population and sample standard deviation, as well as the population and sample variance of the MDD cells.For boolean arrays, the condenser
count_cells()counts the cells containingtrue;some_cells()operation returns true if at least one cell of the boolean MDD istrue,all_cells()returns true if all of the MDD cells containtrueas value.
Please keep in mind that, depending on their nature, operations take a boolean, numeric, or arbitrary mddExp as argument.
Syntax
count_cells( mddExp )
add_cells( mddExp )
avg_cells( mddExp )
min_cells( mddExp )
max_cells( mddExp )
some_cells( mddExp )
all_cells( mddExp )
stddev_pop( mddExp )
stddev_samp( mddExp )
var_pop( mddExp )
var_samp( mddExp )
Examples
The following example returns all images of collection mr where all
pixel values are greater than 20. Note that the induction “>20”
generates a boolean array which, then, can be collapsed into a single
boolean value by the condenser.
select mr
from mr
where all_cells( mr > 20 )
The next example selects all images of collection mr with at least one
pixel value greater than 250 in region [ 120:160, 55:75] (Figure 4.13).
select mr
from mr
where some_cells( mr[120 : 160, 55 : 75] > 250 )
Figure 4.13 Query result of specific selection¶
Finally, this query calculates the sample variance of mr2:
select var_samp( mr2 ) from mr2
4.10.8. SORT operator¶
The SORT operator allows to sort the slices along a given axis of an array.
This is done by calculating a rank value for each of the slices according to a
given ranking function, and then reordering the slices according to their
ranks in ascending (by default) or descending order.
Syntax
SORT generalExp
ALONG sortAxis AS sortAxisIterator [listingOrder]
BY cellExp
Where
sortAxis: integerLit | identifier
sortAxisIterator: identifier
listingOrder: ASC | DESC
The generalExp denotes the array to be sorted; arrays of any dimensionality
and type can be specified, or expressions that produce an array.
The sortAxis along which the array is sliced and reordered is specified in
the ALONG clause. It can be specified by axis name according to the MDD
type definition (e.g. x, y, Lat, …), or by an integer indicating its 0-based
order (0 for the first axis, 1 for the second, and so on). Additionally a
sortAxisIterator must be specified as an alias for addressing the axis in
the ranking function, e.g. in subsetting the generalExp into slices and
aggregating each into a rank. Depending on the optional listingOrder the
slices are sorted in ascending ASC (default if not specified) or descending
DESC order.
The cellExp in the BY clause is the slice ranking function. It must
result in an atomic scalar value for each point in the sort axis extent. Slices
for which the same rank is calculated retain their relative order as in the
input array (stable sorting). The sortAxisIterator can be used to reference
the points along the sortAxis.
The mechanics of the SORT expressions is perhaps more clearly explained via an
equivalence to an MARRAY constructor expression, which creates a 1D array of
ranks calculated by the cellExp for each point in the 1D domain created by
the extend of the sortAxis; then SORT sorts these ranks and the slices to
which they correspond in ascending or descending order. For example, if A is
a 3D array and we have the a SORT expression that reorders the slices along the
first axis by their average values:
SORT A
ALONG 0 AS sortAxis
BY avg_cells( A[ sortAxis[0], *:*, *:* ] )
then before the sorting is applied, first the ranks for each slice are calculated with an MARRAY:
MARRAY sortAxis in [ sdom(A)[0].lo : sdom(A)[0].hi ]
VALUES avg_cells( A[ sortAxis[0], *:*, *:* ] )
The sorting causes no change in the spatial domain, base type, or dimensionality in the result.
Examples
The following examples illustrate the syntax of the SORT operator;
raster2D and raster3D are 2D and 3D MDDs with axes x/y and t/x/y
respectively.
The following examples show the semantics of the sort operator. Array cells which contribute to the rank result are highlighted in red.
expand example
The following example shows how a 10x3 array of double floating-point values is sorted along its second axis in an ascending order by the minimum of all values in each slice.
SORT raster2D ALONG 1 AS i
BY min_cells(raster2D[*:*, i[0]])
The array looks as follows before and after sorting:
Figure 4.14 Minimum values in columns 0,1,2 are 8, 3.26, and 14.8 respectively, highlighted in red.¶
We observe that the sorting was a reordering of the slices along the second axis, represented by the columns.
expand example
By subsetting along an axis other than the sortAxis, we can further restrict
areas in the slices which contribute to the ranking function. For example, the
following 2 queries consider only the value at index positions 0 or 1,
respectively, along axis 1.
SORT raster2D ALONG 0 AS i
BY (raster2D2[i[0], 0])
SORT raster2D ALONG 0 AS i
BY (raster2D2[i[0], 1])
Figure 4.15 Sorting an array with further subsetting each slice along the sort axis.¶
expand example
You might also want to compare two values in a specific axis at once, at each slice, and sort by the minimum value between those, using an aggregate operation:
SORT raster2D ALONG 0 AS i
BY min_cells(raster2D2[i[0], 1:2])
Figure 4.16 Sorting an array by the minimum value with further subsetting at a specific axis.¶
expand example
The next example, shows how a 3D array of double floating-point values for temperature is sorted along its first axis of time in a descending order, by the maximum temperature value in each latitude/longitude combination:
SORT weather ALONG 0 AS i DESC
BY max_cells(weather[i[0], *:*, *:*])
The datasheet looks as follows:
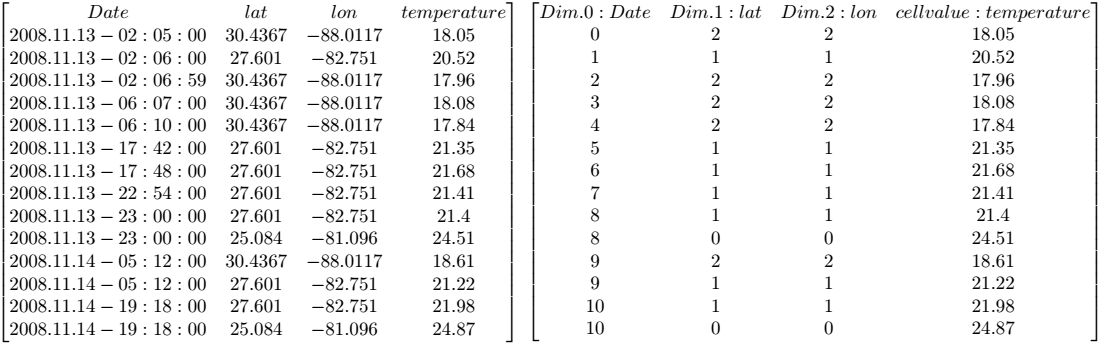
The first datasheet represents all the data that we have. The second offers a datacube interpretation of the available data. The first dimension is time, the second the latitude, and the third represents the longitude. In this example, the lat/lon are limited to 3 entries each. And the temperature is recorded at 11 unique timestamps. Thus, the data is represented using the available combinations of longitude and latitude (25.084,-81.096),(27.601,-82.751) and (30.4367,-88.0117), by (0,0), (1,1) and (2,2) respectively, each in their timestamp. All the cell values are recorded temperatures.
The following illustration represents a 3D array holding this data:

On the first timestamp, for instance, we have a temperature measurement of 18.05 degrees, for lat/lon (2,2), which represents (30.4367,-88.0117) of the original table. In the last timestamp, we have two temperature records, at (0,0) and at (1,1). If we had more measurements, they would fill in the zero-values.
After sorting, the array looks as follows:

We observe that the time-slices have been sorted by their maximum value, in a descending manner.
One can also sort by a specific longitude/latitude combination, e.g:
SORT weather ALONG 0 AS i
BY weather[i[0], 0, 0] DESC
4.10.9. FLIP operator¶
The FLIP operator allows to reverse the values/slices of an MDD along a
particular axis. Similar to SORT, the array is sliced at the chosen axis.
The slices are then reordered in opposite order, resulting in an array
with no change in the spatial domain, base type, or dimensionality.
Syntax
FLIP generalExp ALONG flipAxis
Where
flipAxis: integerLit | identifier
The generalExp denotes the array argument; arrays of any dimensionality
and type can be specified (or expressions that produce an array).
The flipAxis along which the array is sliced and reordered in reverse order
is specified in the ALONG clause. It can be specified by axis name
according to the MDD type definition (e.g. x, y, Lat, …), or by an integer
indicating its 0-based order (0 for the first axis, 1 for the second, and so
on).
Examples
The following examples illustrate the syntax of the FLIP operator;
raster2D and raster3D are 2D and 3D MDDs with axes x/y and time/x/y
respectively.
The next example illustrates the inversion of the following array:

Flipping the array on its first axis with
FLIP raster2D ALONG 0
and flipping on the second axis with
FLIP raster2D ALONG 1
yields the following results, respectively:
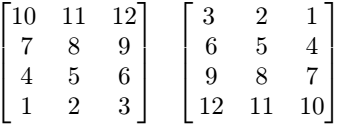
In a more visual example, applying the FLIP operation on the sample MRT imagery
collection mr2 will mirror the image vertically or horizontally. The
original image looks as follows:
flipping on the first axis with
FLIP mr2 ALONG 0
results in
Figure 4.17 the image is mirrored on the vertical axis¶
and flipping on the second axis with
FLIP mr2 ALONG 1
results in
Figure 4.18 the image is mirrored on the horizontal axis¶
4.10.10. General Array Condenser¶
All the condensers introduced above are special cases of a general principle which is represented by the general condenser statement.
The general condense operation consolidates cell values of a multidimensional array to a scalar value based on the condensing operation indicated. It iterates over a spatial domain while combining the result values of the cellExps through the condenserOp indicated.
The general condense operation consolidates cell values of a multidimensional array to a scalar value or an array, based on the condensing operation indicated.
Condensers are heavily used in two situations:
To collapse boolean arrays into scalar boolean values so that they can be used in the where clause.
In conjunction with the marray constructor (see next section) to phrase high-level signal processing and statistical operations.
Syntax
condense condenserOp
over var in mintervalExp
using cellExp
condense condenserOp
over var in mintervalExp
where booleanExp
using cellExp
The mintervalExp terms together span a multidimensional spatial domain over which the condenser iterates. It visits each point in this space exactly once, assigns the point’s respective coordinates to the var variables and evaluates cellExp for the current point. The result values are combined using condensing function condenserOp. Optionally, points used for the aggregate can be filtered through a booleanExp; in this case, cellExp will be evaluated only for those points where booleanExp is true, all others will not be regarded. Both booleanExp and cellExp can contain occurrences of variables pointVar.
Examples
This expression below returns a scalar representing the sum of all array values, multiplied by 2 (effectively, this is equivalent to add_cells(2*a)):
condense +
over x in sdom(a)
using 2 * a[ x ]
The following expression returns a 2-D array where cell values of 3-D array a are added up along the third axis:
condense +
over x in [0:100]
using a[ *:*, *:*, x[0] ]
Note that the addition is induced as the result type of the value clause is an array. This type of operation is frequent, for example, in satellite image time series analysis where aggregation is performed along the time axis.
Shorthands
Definition of the specialized condensers in terms of the general condenser statement is as shown in Table 4.5.
Aggregation definition |
Meaning |
|---|---|
add_cells(a) =
condense +
over x in sdom(a)
using a[x]
|
sum over all cells in a |
avg_cells(a) =
sum_cells(a) /
card(sdom(a))
|
Average of all cells in a |
min_cells(a) =
condense min
over x in sdom(a)
using a [x]
|
Minimum of all cells in a |
max_cells(a) =
condense max
over x in sdom(a)
using a[x]
|
Maximum of all cells in a |
count_cells(b) =
condense +
over x in sdom(b)
where b[x] != 0
using 1
|
Number of cells in b which are non-zero / not false |
some_cells(b) =
condense or
over x in sdom(b)
using b[x]
|
is there any cell in b with value true? |
all_cells(b) =
condense and
over x in sdom(b)
using b[x]
|
do all cells of b have value true? |
Restriction
Currently condensers over complex numbers are generally not supported, with
exception of add_cells and avg_cells.
4.10.11. General Array Constructor¶
The marray constructor allows to create n-dimensional arrays with their content defined by a general expression. This is useful
whenever the array is too large to be described as a constant (see Array Constants) or
when the array’s contents is derived from some other source, e.g., for a histogram computation (see examples below).
Syntax
The basic shape of the marray constructor is as follows:
marray var in mintervalExp [, var in mintervalExp]
values cellExp
The cellExp describes how the resulting array is produced at each point of its domain.
Iterator Variable Declaration
The result array is defined by the cross product of all mintervalExp. For example, the following defines a 2-D 5x10 matrix:
marray x in [1:5], y in [1:10]
values ...
The base type of the array is determined by the type of cellExp. Each variable var can be of any number of dimensions.
Iteration Expression
The resulting array is filled in at each coordinate of its spatial domain by successively evaluating cellExp; the result value is assigned to the cell at the coordinate currently under evaluation. To this end, cellExp can contain arbitrary occurrences of var, which are accordingly substituted with the values of the current coordinate. The syntax for using a variable is:
for a one-dimensional variable:
varfor a one- or higher-dimensional variable:
var [ index-expr ]
where index-expr is a constant expression evaluating to a non-negative integer; this number indicates the variable dimension to be used.

Figure 4.19 2-D array with values derived from first coordinate¶
Examples
The following creates an array with spatial domain [1:100,-50:200] over cell type char, each cell being initialized to 1.
marray x in [ 1:100, -50:200 ]
values 1c
In the next expression, cell values are dependent on the first coordinate component (cf. Figure 4.19):
marray x in [ 0:255, 0:100 ]
values x[0]
The final two examples comprise a typical marray/condenser combination. The first one takes a sales table and consolidates it from days to week per product. Table structure is as given in Figure 4.20.:
select marray tab in [ 0:sdom(s)[0].hi/7, sdom(s)[1] ]
values condense +
over day in [ 0:6 ]
using s[ day[0] + tab7 ] , tab[1] ]
from salestable as s
The last example computes histograms for the mr images. The query creates a 1-D array ranging from 0 to 9 where each cell contains the number of pixels in the image having the respective intensity value.
select marray v in [ 0 : 9 ]
values condense +
over x in sdom(mr)
where mr[x] = v[0]
using 1
from mr
Figure 4.20 Sales table consolidation¶
Shorthand
As a shorthand, variable var can be used without indexing; this is equivalent to var[0]:
marray x in [1:5]
values a[ x ] -- equivalent to a[ x[0] ]
Known issue: the shorthand notation currently works as expected only when one variable is defined.
Many vs. One Variable
Obviously an expression containing several 1-D variables, such as:
marray x in [1:5], y in [1:10]
values a[ x[0], y[0] ]
can always be rewritten to an equivalent expression using one higher-dimensional variable, for example:
marray xy in [1:5, 1:10]
values a[ xy[0], xy[1] ]
Iteration Sequence Undefined
The sequence in which the array cells defined by an marray construct are inspected is not defined. In fact, server optimisation will heavily make use of reordering traversal sequence to achieve best performance.
Restriction
Currently there is a restriction in variable lists: for each marray variable declaration, either there is only one variable which can be multidimensional, or there is a list of one-dimensional variables; mixing the two is not allowed.
A Note on Expressiveness and Performance
The general condenser and the array constructor together allow expressing a very broad range of signal processing and statistical operations. In fact, all other rasql array operations can be expressed through them, as Table 4.6 exemplifies. Nevertheless, it is advisable to use the specialized operations whenever possible; not only are they more handy and easier to read, but also internally their processing has been optimized so that they execute considerably faster than the general phrasing.
operation |
shorthand |
phrasing with marray |
|---|---|---|
Trimming |
a[ *:*, 50:100 ]
|
marray x in [sdom(a)[0], 50:100]
values a[ x ]
|
Section |
a[ 50, *:* ]
|
marray x in sdom(a)[1]
values a[ 50, x ]
|
Induction |
a + b
|
marray x in sdom(a)
values a[x] + b[x]
|
4.10.12. Type Coercion Rules¶
This section specifies the type coercion rules in query expressions, i.e. how the base type of the result from an operation applied on operands of various base types is derived.
The guiding design principle for these rules is to minimize the risk for overflow, but also “type inflation”: when a smaller result type is sufficient to represent all possible values of an operation, then it is preferred over a larger result type. This is especially important in the context of rasdaman, where the difference between float and double for example can be multiple GBs or TBs for large arrays. As such, the rules are somewhat different from C++ for example or even numpy, where in general careful explicit casting is required to avoid overflow or overtyping.
Here a summary is presented, while full details can be explored in rasdaman’s
systemtest.
The type specifiers (c, o, s, …) are the literal type suffixes as documented
in Table 4.2; X and Y indicate any cell type,
U corresponds to any unsigned integer type, S to any signed integer
type, C to any complex type. In every table the upper rows have precedence,
i.e. the deduction rules are ordered; if a particular operand type combination
is missing it means that it is not supported and would lead to a type error. The
first/second operand types are commutative by default and only one direction is
shown to reduce clutter. Types have a rank determined by their size in bytes
and signedness, so that double has a higher rank than float, and long has higher
rank than ulong; max/min of two types returns the type with higher/lower type.
Adding 1 to a type results in the next type by rank, preserving signedness; the
integer/floating-point boundary is not crossed, however, i.e. long + 1 = long.
4.10.12.1. Binary Induced¶
Complex operands are only supported by +, -, \*, /, div, =, and !=. If any
operand of these operations is complex, then the result is complex with
underlying type derived by applying the rules to the underlying types of the
inputs. E.g. char + CInt16 = char + short = CInt32, and CInt32 * CFloat32
= long * float = CFloat64.
*
A special rule for multiplication applicable when one of the operands is boolean. In this case the result type does not change from the non-boolean operand.
first
second
result
X
bool
X
bool
X
X
+, *, div, mod
first
second
result
X
d
d
l,ul
f
d
X
f
f
U1
U2
max(U1, U2) + 1
X
Y
signed(max(X, Y) + 1)
- (subtraction)
The result can always be negative, even if inputs are unsigned (positive), so for integers the result type is always the next greater signed type. Otherwise, the rules are the same as for +, *, div, mod.
first
second
result
X
d
d
l,ul
f
d
X
f
f
X
Y
signed(max(X, Y) + 1)
/ (division)
Division returns floating-point to avoid inadvertent precision loss as well as
unnecessary check for division by zero. Integer division is supported with the
div function.
first
second
result
c,o,s,us,f
c,o,s,us,f
f
X
Y
d
pow, power
Note: operand types are not commutative, the second operand must be a float or double scalar.
first
second
result
c,o,s,us,f
c, o, s, us, f
f
ul,l,d
f, d
d
arctan2
first
second
result
f
f
f
d
d
d
<, >, <=, >=, =, !=
first
second
result
X
Y
bool
min, max, overlay
first
second
result
X
X
X
and, or, xor, is
first
second
result
bool
bool
bool
bit
I stands for any signed and unsigned integer type.
first
second
result
I
I
bool
complex(re, im)
first (re)
second (im)
result
s
s
CInt16
l
l
CInt32
f
f
CFloat32
d
d
CFloat64
4.10.12.2. Unary Induced¶
not
op
result
bool
bool
abs
op
result
C
error
X
X
sqrt, log, ln, exp, sin, cos, tan, sinh, cosh, tanh, arcsin, arccos, arctan
op
result
c,o,us,s,f
f
u,l,d
d
ceil, floor, round
op
result
X
X
4.10.12.3. Condensers¶
count_cells
op
result
bool
ul
add_cells and condense +, *
op
result
C
CFloat64
f,d
d
S
l
U
ul
avg_cells
op
result
C
CFloat64
X
d
stddev_pop, stddev_samp, var_pop, var_samp
op
result
C
error
X
d
min_cells, max_cells and condense min, max
op
result
C
error
X
X
some_cells, all_cells and condense and, or
op
result
bool
bool
4.10.12.4. Geometric Operations¶
The base type does not change in the result of subset, shift, extend, scale, clip, concat, and geographic reprojection.
op
result
X
X
4.10.13. Polygonize operation¶
The polygonize function creates vector polygons for all connected regions of
pixels in a given array, resulting in a vector format file such as Shapefile.
This operation is useful in geographical context, providing ability to layer
additional information on existing maps, for example.
Syntax
polygonize(mddExp, targetFormat)
polygonize(mddExp, targetFormat, connectedness)
polygonize(mddExp, targetFormat, crs, bbox)
polygonize(mddExp, targetFormat, connectedness, crs, bbox)
Where
targetFormat: StringLit
connectedness: integerLit
crs: StringLit
bbox: StringLit
The targetFormat indicates the vector file format in which the result will
be encoded. To check supported targetFormat, refer to the GDAL
documentation. Only those
formats can be used that support creation option.
The connectedness parameter can be set to 4 or 8; if omitted, it will be set
to 4 by default. Setting it to 4 would ensure a ‘true’-cell can only be
considered a neighbor if it shares at least a corner with some
other ‘true’-cell. If we set the connectedness parameter to 8, a ‘true’-cell
can only be a neighbor if it shares a least an edge with some
other ‘true’-cell.
The crs is the geographic CRS of the mddExp. The same CRS formats as GDAL are accepted:
Well Known Text (as per GDAL)
“EPSG:n”
“EPSGA:n”
“AUTO:proj_id,unit_id,lon0,lat0” indicating OGC WMS auto projections
“urn:ogc:def:crs:EPSG::n” indicating OGC URNs (deprecated by OGC)
PROJ.4 definitions
well known names, such as NAD27, NAD83, WGS84 or WGS72.
WKT in ESRI format, prefixed with “ESRI::”
“IGNF:xxx” and “+init=IGNF:xxx”, etc.
Since recently (v1.10), GDAL also supports OGC CRS URLs, OGC’s preferred way of identifying CRSs.
The bbox parameter is a geographic bounding box given as a string of
comma-separated floating-point values of the format: “xmin, ymin, xmax, ymax”.
As a result, the operation produces a file in the desired target format. If the format results in several output files, they will be packaged in a zip archive.
Limitations
The implementation uses GDALPolygonize internally, so it has similar limitations. In particular, arrays with complex values are not supported, and floating-point arrays will be truncated to 64-bit integer. The operation is applicable only on 2-D arrays.
Examples
The following query uses default parameters to polygonize rgb collection:
select polygonize(rgb) from rgb
The result is a .zip archive that consists of the three files in accordance
to the “ESRI Shapefile” format: polygonize.shp, polygonize.shx,
polygonize.dbf
The next query produces the result in pdf format:
select polygonize(rgb, "PDF") from rgb
The retrieved file is polygonize.pdf.
To specify 8-connectedness instead of the default 4, one can use the following query:
select polygonize(rgb, "ESRI Shapefile", 8) from rgb
If the input array is geo-referenced, its CRS and geo bbox can be specified:
select polygonize(c, "EPSG:4326", "-180, -90, 180, 90") from worldmap as c
4.11. Data Format Conversion¶
Without further indication, arrays are accepted and delivered in the client’s main memory format, regardless of the client and server architecture. Sometimes, however, it is desirable to use some data exchange format - be it because some device provides a data stream to be inserted in to the database in a particular format, or be it a Web application where particular output formats have to be used to conform with the respective standards.
To this end, rasql provides two functions for
decoding <rasql-decode-function> format-encoded data into an MDD
encoding <rasql-encode-function> an MDD to a particular format
Implementation of these functions is based on GDAL and, hence, supports all GDAL formats. Some formats are implemented natively in addition: NetCDF, GRIB, JSON, and CSV.
4.11.1. Decode for data import¶
The decode() function allows for decoding data represented in one of
the supported formats, into an MDD which can be persisted or processed in
rasdaman.
4.11.1.1. Syntax¶
decode( mddExp )
encode( mddExp , format , formatParameters )
As a first paramater the data to be decoded must be specified. Technically this
data must be in the form of a 1D char array. Usually it is specified as a query
input parameter with $1, while the binary data is attached with the
--file option of the rasql command-line client tool, or with the
corresponding methods in the client API. If the data is on the same machine as
rasdaman, it can be loaded directly by specifying the path to it in the format
parameters; more details on this in Format parameters.
4.11.1.2. Data format¶
The source data format is automatically detected in case it is handled by GDAL
(e.g. PNG, TIFF, JPEG, etc; see output of gdalinfo --formats or the GDAL
documentation for a full list),
so there is no format parameter in this case.
A format is necessary, however, when a custom internal implementation should be
selected instead of GDAL for decoding the data, e.g. NetCDF ("netcdf" /
"application/netcdf"), GRIB ("grib"), JSON ("json" /
"application/json"), or CSV ("csv" / "text/csv").
4.11.1.3. Format parameters¶
Optionally, a format parameters string can be specified as a third parameter,
which allows to control the format decoding. For GDAL formats it is necessary to
specify format "GDAL" in this case.
The format parameters must be formatted as a valid JSON object. As the format
parameters are in quotes, i.e. "formatParameters", all quotes inside of the
formatParameters need to be escaped (\"). For example,
"{ \"transpose\": [0,1] }" is the right way to specify transposition, while
"{ "transpose": [0,1] }" will lead to failure. Note that in examples further
on quotes are not escaped for readability.
4.11.1.3.1. Common parameters¶
The following parameters are common to GDAL, NetCDF, and GRIB data formats:
variables- An array of variable names or band ids (0-based, as strings) to be extracted from the data. This allows to decode only some of the variables in a NetCDF file for example with["var1", "var2"], or the bands of a TIFF file with["0", "2"].filePaths- An array of absolute paths to input files to be decoded, e.g.["/path/to/rgb.tif"]. This improves ingestion performance if the data is on the same machine as the rasdaman server, as the network transport is bypassed and the data is read directly from disk. Supported only for GDAL, NetCDF, and GRIB data formats.subsetDomain- Specify a subset to be extracted from the input file, instead of the full data. The subset should be specified in rasdaman minterval format as a string, e.g."[0:100,0:100]". Note that the subset domain must match in dimensionality with the file dimensionality, and must be accordingly offset to the grid origin in the file, which is typically [0,0,0,…].transpose- Specify if x/y should be transposed with an array of 0-based axis ids indicating the axes that need to be transposed; the axes must be contiguous[N,N+1], e.g.[0,1]. This is often relevant in NetCDF and GRIB data which have a swapped x/y order than what is usually expected in e.g. GDAL. Note that transposing axes has a performance penalty, so avoid if possible.formatParameters- A JSON object containing extra options which are format-specific, specified as string key-value pairs. This is where one would specify the base type and domain for decoding a CSV file for example, or GDAL format-specific options. Example for a CSV file:"formatParameters": { "basetype": "struct { float f, long l }", "domain": "[0:100,0:100]" }
4.11.1.3.2. GDAL¶
formatParameters- any entries in the formatParameters object are forwarded to the specific GDAL driver; consult the GDAL documentation for the options recognized by each particular driver. E.g. for PNG you could specify, among other details, a description metadata field with:"formatParameters": { "DESCRIPTION": "Data description..." }
configOptions- A JSON object containing configuration options as string key-value pairs; more details in the GDAL documentation. Example:"configOptions": { "GDAL_CACHEMAX": "64", ... }
openOptions- A JSON object containing open options as string key-value pairs; an option for selecting overview level from the file with, e.g."OVERVIEW_LEVEL": "2", is available for all formats (more details); further options may be supported by each driver, e.g. for TIFF;"openOptions": { "OVERVIEW_LEVEL": "2", "NUM_THREADS": "ALL_CPUS" }
Note
This feature is only available since GDAL 2.0, so if you have an older GDAL these options will be ignored.
4.11.1.3.3. GRIB¶
internalStructure- Describe the internal structure of a GRIB file, namely the domains of all messages to be extracted from the file:"internalStructure": { "messageDomains": [ { "msgId": 1, "domain": "[0:0,0:0,0:719,0:360]" }, { "msgId": 2, "domain": "[0:0,1:1,0:719,0:360]" }, { "msgId": 3, "domain": "[0:0,2:2,0:719,0:360]" }, ... ] }
4.11.1.3.4. CSV / JSON¶
The following are mandatory options that have to be specified in the
formatParameters object:
domain- The domain of the MDD encoded in the CSV data. It has to match the number of cells read from input file, e.g. for"domain": "[1:5, 0:10, 2:3]", there should be 110 numbers in the input file.basetype- Atomic or struct base type of the cell values in the CSV data; named structs likeRGBPixelare not supported. Examples:long char struct { char red, char blue, char green }
Numbers from the input file are read in order of appearance and stored without any reordering in rasdaman; whitespace plus the following characters are ignored:
'{', '}', ',', '"', '\'', '(', ')', '[', ']'
4.11.1.4. Examples¶
4.11.1.4.1. GDAL¶
The following query loads a TIFF image into collection rgb:
rasql -q 'insert into rgb values decode( $1 )' --file rgb.tif
If you use double quotes for the query string, note that the $ must be
escaped to avoid interpretation by the shell:
rasql -q "insert into rgb values decode( \$1 )" --file rgb.tif
The example below shows directly specifying a file path in the format parameters;
<[0:0] 1c> is a dummy array value which is not relevant in this case, but is
nevertheless mandatory:
UPDATE test_mr SET test_mr[0:255,0:210]
ASSIGN decode(<[0:0] 1c>, "GDAL",
"{ \"filePaths\": [\"/home/rasdaman/mr_1.png\"] }")
WHERE oid(test_mr) = 6145
4.11.1.4.2. CSV / JSON¶
Let array A be a 2x3 array of longs given as a string as follows:
1,2,3,2,1,3
Inserting A into rasdaman can be done with
insert into A
values decode($1, "csv", "{ \"formatParameters\": {
\"domain\": \"[0:1,0:2]\",
\"basetype\": \"long\" } }")
Further, let B be an 1x2 array of RGB values given as follows:
{1,2,3},{2,1,3}
Inserting B into rasdaman can be done by passing it to this query:
insert into B
values decode($1, "csv", "{ \"formatParameters\": {
\"domain\": \"[0:0,0:1]",
\"basetype\": \"struct{char red, char blue, char green}\" } }")
B could just as well be formatted like this with the same effect (note
the line break):
1 2 3
2 1 3
4.11.2. Encode for data export¶
The encode() function allows encoding an MDD in a particular data format
representation; formally, the result will be a 1D char array.
4.11.2.1. Syntax¶
encode( mddExp , format )
encode( mddExp , format , formatParameters )
The first parameter is the MDD to be encoded. It must be 2D if encoded to GDAL formats (PNG, TIFF, JPEG, etc.), while the native rasdaman encoders (NetCDF, JSON, and CSV) support MDDs of any dimension; note that presently encode to GRIB is not supported. As not all base types supported by rasdaman (char, octet, float, etc.) are necessarily supported by each format, care must be taken to cast the MDD beforehand.
4.11.2.2. Data format¶
A mandatory format must be specified as the second parameter, indicating
the data format to which the MDD will be encoded; allowed values are
GDAL format identifiers (see output of
gdalinfo --formatsor the GDAL documentation);a mime-type string, e.g.
"image/png";"netcdf"/"application/netcdf","csv"/"text/csv", or"json"/"application/json", for formats natively supported by rasdaman.
4.11.2.3. Format parameters¶
Optionally, a format parameters string can be specified as a third parameter,
which allows to control the format encoding. As in the case of decode(), it must
be a valid JSON object. As the format parameters are in quotes, i.e.
"formatParameters", all quotes inside of the formatParameters need to be
escaped (\"). For example, "{ \"transpose\": [0,1] }" is the right way
to specify transposition, while "{ "transpose": [0,1] }" will lead to
failure.
Common parameters to most or all formats include:
metadata- A single string, or an object of string key-value pairs which are added as global metadata when encoding.transpose- Specify if x/y should be transposed with an array of 0-based axis ids indicating the axes that need to be transposed; the axes must be contiguous[N,N+1], e.g.[0,1]. This is often relevant when encoding data with GDAL formats, which was originally imported from NetCDF and GRIB files. Note that transposing axes has a performance penalty, so avoid if possible.nodata- Specify nodata value(s). If a single number is specified it will be applicable to all bands (e.g.0), otherwise an array of numbers for each band can be provided (e.g.[0,255,255]). Special floating-point constants are supported (case-sensitive): NaN, NaNf, Infinity, -Infinity.formatParameters- A JSON object containing extra options which are format-specific, specified as string key-value pairs. This is where one would specify the options for controling what separators and values are used in CSV encoding for example, or GDAL format-specific options.
4.11.2.3.1. GDAL¶
formatParameters- any entries in the formatParameters object are forwarded to the specific GDAL driver; consult the GDAL documentation for the options recognized by each particular driver. E.g. for PNG you could specify, among other details, a description metadata field with:"formatParameters": { "DESCRIPTION": "Data description..." }
Rasdaman itself does not change the default values for these parameters, with the following exceptions:
PNG- the compression level when encoding to PNG (optionZLEVEL) will be set to2if the user does not specify it explicitly and the result array is not of typeboolean. The default compression level of6does not offer considerable space savings on typical image results (e.g. around 10% lower file size for satellite image), while significantly increasing the time to encode, taking up to 3-5x longer.
configOptions- A JSON object containing configuration options as string key-value pairs; only relevant for GDAL currently, more details in the GDAL documentation. Example:"configOptions": { "GDAL_CACHEMAX": "64", ... }
Geo-referencing¶
geoReference- An object specifying geo-referencing information; either “bbox” or “GCPs” must be provided, along with the “crs”:crs- Coordinate Reference System (CRS) in which the coordinates are expressed. Any of the CRS representations acceptable by GDAL can be used:Well known names, such as
"NAD27","NAD83","WGS84"or"WGS72""EPSG:n","EPSGA:n"PROJ.4 definitions
OpenGIS Well Known Text
ESRI Well Known Text, prefixed with
"ESRI::"Spatial References from URLs
"AUTO:proj_id,unit_id,lon0,lat0"indicating OGC WMS auto projections"urn:ogc:def:crs:EPSG::n"indicating OGC URNs (deprecated by OGC)
bbox- A geographic X/Y bounding box as an object listing the coordinate values (as floating-point numbers) forxmin,ymin,xmax, andymaxproperties, e.g.:"bbox": { "xmin": 0.0, "ymin": -1.0, "xmax": 1.0, "ymax": 2.0 }
GCPs- Alternative to abbox, an array of GCPs (Ground Control Points) can be specified; see GCPs section in the GDAL documentation for details. Each element of the array is an object describing one control point with the following properties:id- optional unique identifier (gets the GCP array index by default);info- optional text associated with the GCP;pixel,line- location on the array grid;x,y,z- georeferenced location with coordinates in the specified CRS; “z” is optional (zero by default);
Coloring Arrays¶
colorMap- Map single-band cell values into 1, 3, or 4-band values. It can be done in different ways depending on the specified type:values- Each pixel is replaced by the entry in thecolorTablewhere the key is the pixel value. In the example below, it means that all pixels with value -1 are replaced by [255, 255, 255, 0]. Pixels with values not present in the colorTable are not rendered: they are replaced with a color having all components set to 0."colorMap": { "type": "values", "colorTable": { "-1": [255, 255, 255, 0], "-0.5": [125, 125, 125, 255], "1": [0, 0, 0, 255] } }
intervals- All pixels with values between two consecutive entries are rendered using the color of the first (lower-value) entry. Pixels with values equal to or less than the minimum value are rendered with the bottom color (and opacity). Pixels with values equal to or greater than the maximum value are rendered with the top color and opacity."colorMap": { "type": "intervals", "colorTable": { "-1": [255, 255, 255, 0], "-0.5": [125, 125, 125, 255], "1": [0, 0, 0, 255] } }
In this case, all pixels with values in the interval (-inf, -0.5) are replaced with [255, 255, 255, 0], pixels in the interval [-0.5, 1) are replaced with [125, 125, 125, 255], and pixels with value >= 1 are replaced with [0, 0, 0, 255].
ramp- Same as “intervals”, but instead of using the color of the lowest value entry, linear interpolation between the lowest value entry and highest value entry, based on the pixel value, is performed."colorMap": { "type": "ramp", "colorTable": { "-1": [255, 255, 255, 0], "-0.5": [125, 125, 125, 255], "1": [0, 0, 0, 255] } }
Pixels with value -0.75 are replaced with color [189, 189, 189, 127], because they sit in the middle of the distance between -1 and -0.5, so they get, on each channel, the color value in the middle. The interpolation formula for a pixel of value x, where 2 consecutive entries in the colorTable \(a, b\) with \(a \le x \le b\), is:
\[resultColor = \frac{b - x}{b - a} * colorTable[b] + \frac{x - a}{b - a} * colorTable[a]\]For the example above, a = -1, x = -0.75, b = -0.5, colorTable[a] = [255, 255, 255, 0], colorTable[b] = [125, 125, 125, 255], so:
\[\begin{split}resultColor &= \frac{-0.5 + 0.75}{-0.5 + 1} * [255, 255, 255, 0] + \\ & \hspace{1.5em} \frac{-0.75 + 1}{-0.5 + 1} * [125, 125, 125, 255] \\ &= 0.5 * [255, 255, 255, 0] + 0.5 * [125, 125, 125, 255] \\ &= [127, 127, 127, 0] + [62, 62, 62, 127] \\ &= [189, 189, 189, 127] \\\end{split}\]Note the integer division, because the colors are of type unsigned char.
colorPalette- Similar tocolorMap, however, it allows specifying color information on a metadata level, rather than by actually transforming array pixel values; for details see the GDAL documentation. It is an object that contains several optional properties:paletteInterp- Indicate how the entries in the colorTable should be interpreted; allowed values are “Gray”, “RGB”, “CMYK”, “HSL” (default “RGB”);colorInterp- Array of color interpretations for each band; allowed values are Undefined, Gray, Palette, Red, Green, Blue, Alpha, Hue, Saturation, Lightness, Cyan, Magenta, Yellow, Black, YCbCr_Y, YCbCr_Cb, YCbCr_Cr, YCbCr_Cr;colorTable- Array of arrays, each containing 1, 3, or 4 short values (depending on thecolorInterp) for each color entry; to associate a color with an array cell value, the cell value is used as a subscript into the color table (starting from 0).
4.11.2.3.2. NetCDF¶
The following are mandatory options when encoding to NetCDF:
dimensions- An array of names for each dimension, e.g.["Lat","Long"].variables- Specify variable names for each band of the MDD, dimension names if they need to be saved as coordinate variables, as well as non-data grid mapping variables. There are three ways to specify the variables:An array of strings for each variable name, e.g.
["var1", "var2"]; no coordinate variables should be specified in this case, as there is no way to specify the data for them;An array of variable objects, where each object lists the following variable details:
name- The variable name, e.g."name": "var1"metadata- An object of string key-value pairs which are added as attributes to the variable;type- Type of the data values this variable contains relevant (and required) for coordinate or non-data variables; allowed values are “byte”, “char”, “short”, “ushort”, “int”, “uint”, “float”, and “double”;data- An array of data values for the variable relevant (and required) only for coordinate variables (as regular variables get their data values from the array to be encoded); the number of values must match the dimension extent;
If the variable name is not listed in the
dimensionsarray and still has adataattribute, then it will be considered to be a non-data variable and will not be used for storing MDD band data; thedataattribute is ignored in this case, so the value for it can be an empty JSON array[].An object of variable name - object pairs, where each object lists the variable details in similar fashion to the option 2. above, except that the key
nameis optional. This way of specifying the variables in a JSON object is deprecated because their order is non-deterministic and may not work as expected when encoding multiple variables. It is recommended to use the method in option 2.
4.11.2.3.3. CSV / JSON¶
Data encoded with CSV or JSON is a comma-separated list of values, such that
each row of values (for every dimension, not just the last one) is between {
and } braces ([ and ] for JSON). The table below documents all
“formatParameters” options that allow controlling the output, and the default
settings for both formats.
option |
description |
CSV default |
JSON default |
|---|---|---|---|
|
array linearization order, can be “outer_inner” (default, last dimension iterates fastest, i.e. column-major for 2-D), or vice-versa, “inner_outer”. |
“outer_inner” |
“outer_inner” |
|
string denoting true values |
“t” |
“true” |
|
string denoting false values |
“f” |
“false” |
|
string to indicate starting a new dimension slice |
“{“ |
“[“ |
|
string to indicate ending a dimension slice |
“}” |
“]” |
|
separator between dimension slices |
“,” |
“,” |
|
separator between cell values |
“,” |
“,” |
|
separator between components of struct cell values |
” “ |
” “ |
|
string to indicate starting a new struct value |
“\"” |
“\"” |
|
string to indicate ending a new struct value |
“\"” |
“\"” |
|
wrap output in dimensionStart and dimensionEnd |
false |
true |
4.11.2.4. Examples¶
4.11.2.4.1. GDAL¶
This query extracts PNG images (one for each tuple) from collection mr:
select encode( mr, "png" )
from mr
Transpose the last two axes of the output before encoding to PNG:
select encode(c, "png", "{ \"transpose\": [0,1] }") from mr2 as c
4.11.2.4.2. NetCDF¶
Add some global attributes as metadata in netcdf:
select encode(c, "netcdf", "{ \"transpose\": [1,0], \"nodata\": [100],
\"metadata\": { \"new_metadata\": \"This is a new added metadata\" } }")
from test_mean_summer_airtemp as c
The format parameters below specify the variables to be encoded in the result
NetCDF file (Lat, Long, forecast, and drought_code); of these Lat, Long, and
forecast are dimension variables for which the values are specified in the
"data" array, which leaves drought_code is the proper variable for encoding
the array data.
Below format parameters for a rotated grid are specified, which define a
"rotated_pole" grid mapping variable in addition to the dimension variables
(rlong and rlat) and the band variable CAPE_ML. More information on
grid mappings can be found here.
4.11.2.4.3. CSV / JSON¶
Suppose we have array A = <[0:1,0:1] 0, 1; 2, 3>. Encoding to CSV by default
select encode(A, "csv") from A
will result in the following output:
{{0, 1}, {2, 3}}
while encoding to JSON with:
select encode(A, "json") from A
will result in the following output:
[[0, 1], [2, 3]]
Specifying inner_outer order with
select encode(A, "csv", "{ \"formatParameters\":
{ \"order\": \"inner_outer\" } }") from A
will result in the following output (left-most dimensions iterate fastest):
{{0, 2}, {1, 3}}
Let B be an RGB array <[0:0,0:1] {0c, 1c, 2c}, {3c, 4c, 5c}>. Encoding it
to CSV with default order will result in the following output:
{“0 1 2”,”3 4 5”}
4.12. Object identifiers¶
Function oid() gives access to an array’s object identifier (OID). It
returns the local OID of the database array. The input parameter must be
a variable associated with a collection, it cannot be an array
expression. The reason is that oid() can be applied to only to
persistent arrays which are stored in the database; it cannot be applied
to query result arrays - these are not stored in the database, hence do
not have an OID.
Syntax
oid( variable )
Example
The following example retrieves the MDD object with local OID 10 of set
mr:
select mr
from mr
where oid( mr ) = 10
The following example is incorrect as it tries to get an OID from a non-persistent result array:
select oid( mr * 2 ) -- illegal example: no expressions
from mr
Fully specified external OIDs are inserted as strings surrounded by brackets:
select mr
from mr
where oid( mr ) = < localhost | RASBASE | 10 >
In that case, the specified system (system name where the database server runs) and database must match the one used at query execution time, otherwise query execution will result in an error.
4.12.1. Expressions¶
Parentheses
All operators, constructors, and functions can be nested arbitrarily, provided that each sub-expression’s result type matches the required type at the position where the sub-expression occurs. This holds without limitation for all arithmetic, Boolean, and array-valued expressions. Parentheses can (and should) be used freely if a particular desired evaluation precedence is needed which does not follow the normal left-to-right precedence.
Example
select (rgb.red + rgb.green + rgb.blue) / 3c
from rgb
Operator Precedence Rules
Sometimes the evaluation sequence of expressions is ambiguous, and the different evaluation alternatives have differing results. To resolve this, a set of precedence rules is defined. You will find out that whenever operators have their counterpart in programming languages, the rasdaman precedence rules follow the same rules as are usual there.
Here the list of operators in descending strength of binding:
dot “.”, trimming, section
unary
-sqrt,sin,cos, and other unary arithmetic functions*,/+,-<,<=,>,>=,!=,=andor,xor“:” (interval constructor),
condense,marrayoverlay,concatIn all remaining cases evaluation is done left to right.
4.13. Null Values¶
“Null is a special marker used in Structured Query Language (SQL) to indicate that a data value does not exist in the database. NULL is also an SQL reserved keyword used to identify the Null special marker.” (Wikipedia) In fact, null introduces a three-valued logic where the result of a Boolean operation can be null itself; likewise, all other operations have to respect null appropriately. Said Wikipedia article also discusses issues the SQL language has with this three-valued logic.
For sensor data, a Boolean null indicator is not enough as null values can mean many different things, such as “no value given”, “value cannot be trusted”, or “value not known”. Therefore, rasdaman refines the SQL notion of null:
Any value of the data type range can be chosen to act as a null value;
a set of cell values can be declared to act as null (in contrast to SQL where only one null per attribute type is foreseen).
Caveat
Note that defining values as nulls reduces the value range available for known values. Additionally, computations can yield values inadvertently (null values themselves are not changed during operations, so there is no danger from this side). For example, if 5 is defined to mean null then addition of two non-null values, such as 2+3, yields a null.
Every bit pattern in the range of a numeric type can appear in the database, so no bit pattern is left to represent “null”. If such a thing is desired, then the database designer must provide, e.g., a separate bit map indicating the status for each cell.
To have a clear semantics, the following rule holds:
Uninitialized value handling
A cell value not yet addressed, but within the current domain of an MDD has a value of zero by definition; this extends in the obvious manner to composite cells.
Remark
Note the limitation to the current domain of an MDD. While in the case of an MDD with fixed boundaries this does not matter because always definition domain = current domain, an MDD with variable boundaries can grow and hence will have a varying current domain. Only cells inside the current domain can be addressed, be they uninitialized/null or not; addressing a cell outside the current domain will result in the corresponding exception.
Masks as alternatives to null
For example, during piecewise import of satellite images into a large map, there will be areas which are not written yet. Actually, also after completely creating the map of, say, a country there will be untouched areas, as normally no country has a rectangular shape with axis-parallel boundaries. The outside cells will be initialized to 0 which may or may not be defined as null. Another option is to define a Boolean mask array of same size as the original array where each mask value contains true for “cell valid” and false for “cell invalid. It depends on the concrete application which approach benefits best.
4.13.1. Nulls in MDD-Valued Expressions¶
Dynamically Set/Replace the Null Set
The null set of an MDD value resulting from a sub-expression can be dynamically
changed on-the-fly with a postfix null values operator as follows:
mddExp null values nullSet
As a result mddExp will have the null values specified by nullSet; if mddExp already had a null set, it will be replaced.
Null Set Propagation
The null value set of an MDD is part of its type definition and, as such, is carried along over the MDD’s lifetime. Likewise, MDDs which are generated as intermediate results during query processing have a null value set attached. Rules for constructing the output MDD null set are as follows:
The null value set of an MDD generated through an
marrayoperation is empty 13.The null value set of an operation with one input MDD object is identical to the null set of this input MDD.
The null value set of an operation with two input MDD objects is the union of the null sets of the input MDDs.
The null value set of an MDD expression with a postfix
null valuesoperator is equal to the null set specified by it.
Null Values in Operations
Subsetting (trim and slice operations, as well as struct selection,
etc.) perform just as without nulls and deliver the original cell
values, be they null (relative to the MDD object on hand) or not. The
null value set of the output MDD is the same as the null value set of
the input MDD.
In MDD-generating operations with only one input MDD (such as marray and unary induced operations), if the operand of a cell operation is null then the result of this cell operation is null.
Generally, if somewhere in the input to an individual cell value computation a null value is encountered then the overall result will be null - in other words: if at least one of the operands of a cell operation is null then the overall result of this cell operation is null.
Exceptions:
Comparison operators (that is:
==,!=,>,>=,<,<=) encountering a null value will always return a Boolean value; for example, bothn == nandn != n(for any null valuen) will evaluate tofalse.In a cast operation, nulls are treated like regular values.
In a
scale()operation, null values are treated like regular values 14.Format conversion of an MDD object ignores null values. Conversion from some data format into an MDD likewise imports the actual cell values; however, during any eventual further processing of the target MDD as part of an update or insert statement, cell values listed in the null value set of the pertaining MDD definition will be interpreted as null and will not overwrite persistent non-null values.
Choice of Null Value
If an operation computes a null value for some cell, then the null value effectively assigned is determined from the MDD’s type definition.
If the overall MDD whose cell is to be set has exactly one null value, then this value is taken. If there is more than one null value available in the object’s definition, then one of those null values is picked non-deterministically. If the null set of the MDD is empty then no value in the MDD is considered a null value.
Example
Assume an MDD a holding values <0, 1, 2, 3, 4, 5> and a null value set
of {2, 3}. Then, a*2 might return <0, 2, 2, 2, 8, 10>. However,
<0, 2, 3, 3, 8, 10> and <0, 2, 3, 2, 8, 10> also are valid results, as
the null value gets picked non-deterministically.
4.13.2. Nulls in Aggregation Queries¶
In a condense operation, cells containing nulls do not contribute to the overall result (in plain words, nulls are ignored).
If all values are null, then the result is the identity element in this case,
e.g. 0 for +, true for and, false for or, maximum value
possible for the result base type for min, minimum value possible for the
result base type for max, 0 for count_cells.
The scalar value resulting from an aggregation query does not carry a null value set like MDDs do; hence, during further processing it is treated as an ordinary value, irrespective of whether it has represented a null value in the MDD acting as input to the aggregation operation.
4.13.3. Limitations¶
All cell components of an MDD share the same same set of nulls, it is currently not possible to assign individual nulls to cell type components.
4.13.4. NaN Values¶
NaN (“not a number”) is the representation of a numeric value representing an undefined or unrepresentable value, especially in floating-point calculations. Systematic use of NaNs was introduced by the IEEE 754 floating-point standard (Wikipedia).
In rasql, nan (double) and nanf (float) are symbolic floating point
constants that can be used in any place where a floating point value is allowed.
Arithmetic operations involving nans always result in nan. Equality
and inequality involving nans work as expected, all other comparison operators
return false.
If the encoding format used supports NaN then rasdaman will encode/decode NaN values properly.
Example
select count_cells( c != nan ) from c
4.14. Miscellaneous¶
4.14.1. rasdaman version¶
Builtin function version() returns a string containing information about the rasdaman version of the server, and the gcc version used for compiling it. The following query
select version()
will generate a 1-D array of cell type char containing contents similar to the following:
rasdaman 9.6.0 on x86_64-linux-gnu, compiled by g++
(Ubuntu 5.4.1-2ubuntu1~16.04) 5.4.1 20160904
Warning
The message syntax is not standardized in any way and may change in any rasdaman version without notice.
4.14.2. Retrieving Object Metadata¶
Sometimes it is desirable to retrieve metadata about a particular array.
To this end, the dbinfo() function is provided. It returns a 1-D char
array containing a JSON encoding of key array metadata:
Object identifier;
Base type, mdd type name, set type name;
Total size of the array;
Number of tiles and further tiling information: tiling scheme, tile size (if specified), and tile configuration;
Index information: index type, and further details depending on the index type.
The output format is described below by way of an example.
Syntax
dbinfo( mddExp )
dbinfo( mddExp , formatParams )
Example
$ rasql -q 'select dbinfo(c) from mr2 as c' --out string
{
"oid": "150529",
"baseType": "marray <char>",
"mddTypeName": "GreyImage",
"setTypeName": "GreySet",
"tileNo": "1",
"totalSize": "54016B",
"tiling": {
"tilingScheme": "no_tiling",
"tileSize": "2097152",
"tileConfiguration": "[0:511,0:511]"
},
"index": {
"type": "rpt_index",
"indexSize": "0",
"PCTmax": "4096B",
"PCTmin": "2048B"
}
}
The function supports a string of format parameters as the second argument. By now the only supported parameter is printTiles. It can take multiple values: “embedded”, “json”, “svg”. Example of syntax:
select dbinfo(c, "printtiles=svg") from test_overlap as c
Parameter “printiles=embedded” will print additionally domains of every tile.
$ rasql -q 'select dbinfo(c, "printtiles=embedded") from test_grey as c' --out string
{
"oid": "136193",
"baseType": "marray <char, [*:*,*:*]>",
"setTypeName": "GreySet",
"mddTypeName": "GreyImage",
"tileNo": "48",
"totalSize": "54016",
"tiling": {
"tilingScheme": "aligned",
"tileSize": "1500",
"tileConfiguration": "[0:49,0:29]"",
"tileDomains":
[
"[100:149,210:210]",
"[150:199,0:29]",
"[150:199,30:59]",
"[150:199,60:89]",
"[150:199,90:119]",
"[150:199,120:149]",
"[150:199,150:179]",
"[150:199,180:209]",
"[150:199,210:210]",
"[200:249,0:29]",
"[200:249,30:59]",
"[200:249,60:89]",
"[200:249,90:119]",
"[200:249,120:149]",
"[200:249,150:179]",
"[200:249,180:209]",
"[200:249,210:210]",
"[250:255,0:29]",
"[250:255,30:59]",
"[250:255,60:89]",
...
]
},
"index": {
"type": "rpt_index",
"PCTmax": "4096",
"PCTmin": "2048"
}
}
Option “json” will output only the tile domains as a json object.
["[100:149,210:210]","[150:199,0:29]",..."[0:49,30:59]"]
Last option “svg” will output tiles as svg that can be visualised. Example:
<svg width="array width" height="array height">
<rect x="100" y="210" width="50" height="1" id="1232"></rect>
<rect x="150" y="0" width="50" height="30" id="3223"></rect>
...
</svg>
Note
This function can only be invoked on persistent MDD objects, not on derived (transient) MDDs.
Warning
This function is in beta version. While output syntax is likely to remain largely unchanged, invocation syntax is expected to change to something like
describe array oidExp
4.15. Arithmetic Errors and Other Exception Situations¶
During query execution, a number of situations can arise which prohibit to deliver the desired query result or database update effect. If the server detects such a situation, query execution is aborted, and an error exception is thrown. In this Section, we classify the errors that occur and describe each class.
However, we do not go into the details of handling such an exception - this is the task of the application program, so we refer to the resp. API Guides.
4.15.1. Overflow¶
Candidates
Overflow conditions can occur with add_cells and induced operations such
as +.
System Reaction
The overflow will be silently ignored, producing a result represented by the bit pattern pruned to the available size. This is in coherence with overflow handling in performance-oriented programming languages.
Remedy
Query coding should avoid potential overflow situations by applying numerical knowledge - simply said, the same care should be applied as always when dealing with numerics.
It is worth being aware of the type coercion rules <type-coercion> in rasdaman and overflow handling in C++. The type coercion rules have been crafted to avoid overflow as much as possible, but of course it remains a possibility. Adding or multiplying two chars for example is guaranteed to not overflow. However, adding or multyplying two ulongs would result in a ulong by default, which may not be large enough to hold the result. Therefore, it may be worth casting to double in this case based on knowledge about the data.
Checking for overflow with a case statement like the below will not work as one might expect and is hence not recommended:
case
when a.longatt1 * a.longatt2 > 2147483647 then 2147483647
else a.longatt1 * a.longatt2
end
If a.longatt1 * a.longatt2 overflows, the result is undefined behavior
according to C++ so it is not clear what the result value would be in this case.
It will never be larger than the maximum value of 32-bit signed integer,
however, because that is the result type according to the type coercion rules.
Hence the comparison to 2147483647 (maximum value of 32-bit signed integer) will
never return true.
4.15.2. Illegal operands¶
Candidates
Division by zero, non-positive argument to logarithm, negative arguments to the square root operator, etc. are the well-known candidates for arithmetic exceptions.
The IEEE 754 standard lists, for each operation, all invalid input and the corresponding operation result (Sections Select Clause: Result Preparation, From Clause: Collection Specification, Multidimensional Intervals). Examples include:
division(0,0), division(INF,INF)
sqrt(x) where x < 0
log(x) where x < 0
System Reaction
In operations returning floating point numbers, results are produced in conformance with IEEE 754. For example, 1/0 results in nan.
In operations returning integer numbers, results for illegal operations are as follows:
div(x, 0)leads to a “division by zero” exceptionmod(x, 0)leads to a “division by zero” exception
Remedy
To avoid an exception the following code is recommended for a div b
(replace accordingly for mod), replacing all illegal situations with a
result of choice, c:
case when b = 0 then c else div(a, b) end
If the particular situation allows, it may be more efficient to cast to floating-point, and cast back to integer after the division (if an integer result is wanted):
(long)((double)a / b)
Division by 0 will result in Inf in this case, which turns into 0 when cast to integer.
4.15.3. Access Rights Clash¶
If a database has been opened in read-only mode, a write operation will be refused by the server; “write operation” meaning an insert, update, or delete statement.
4.16. Database Retrieval and Manipulation¶
4.16.1. Collection Handling¶
4.16.1.1. Create a Collection¶
The create collection statement is used to create a new, empty MDD collection by specifying its name and type. The type must exist in the database schema. There must not be another collection in this database bearing the name indicated.
Syntax
create collection collName typeName
Example
create collection mr GreySet
4.16.1.2. Drop a Collection¶
A database collection can be deleted using the drop collection statement.
Syntax
drop collection collName
Example
drop collection mr1
4.16.1.3. Alter Collection¶
The type of a collection can be changed using the alter collection statement.
The new collection type is accordingly checked for compatibility (same cell type,
dimensionality) as the existing type of the collection before setting it.
Syntax
alter collection collName
set type newCollType
Example
alter collection mr2
set type GreySetWithNullValues
4.16.1.4. Retrieve All Collection Names¶
With the following rasql statement, a list of the names of all collections currently existing in the database is retrieved; both versions below are equivalent:
select RAS_COLLECTIONNAMES
from RAS_COLLECTIONNAMES
select r
from RAS_COLLECTIONNAMES as r
Note that the meta collection name, RAS_COLLECTIONNAMES, must be written in
upper case only. No operation in the select clause is permitted. The
result is a set of one-dimensional char arrays, each one holding the
name of a database collection. Each such char array, i.e., string is
terminated by a zero value (‘0’).
4.16.2. Select¶
The select statement allows for the retrieval from array collections. The result is a set (collection) of items whose structure is defined in the select clause. Result items can be arrays or scalar values. In the where clause, a condition can be expressed which acts as a filter for the result set. A single query can address several collections.
Syntax
select resultList
from collName [ as collIterator ]
[, collName [ as collIterator ] ] ...
select resultList
from collName [ as collIterator ]
[, collName [ as collIterator ] ] ...
where booleanExp
Examples
This query delivers a set of grayscale images:
select mr[100:150,40:80] / 2
from mr
where some_cells( mr[120:160, 55:75] > 250 )
This query, on the other hand, delivers a set of integers:
select count_cells( mr[120:160, 55:75] > 250 )
from mr
4.16.3. Insert¶
MDD objects can be inserted into database collections using the insert statement. The array to be inserted must conform with the collection’s type definition concerning both cell type and spatial domain. One or more variable bounds in the collection’s array type definition allow degrees of freedom for the array to be inserted. Hence, the resulting collection in this case can contain arrays with different spatial domain.
Syntax
insert into collName
values mddExp
collName specifies the name of the target set, mddExp describes the array to be inserted.
Example
Add a black image to collection mr1.
insert into mr1
values marray x in [ 0:255, 0:210 ]
values 0c
See the programming interfaces described in the
rasdaman Developer’s Guides on how to ship external array data to the
server using insert and update statements.
4.16.4. Update¶
The update statement allows to manipulate arrays of a collection. Which elements of the collection are affected can be determined with the where clause; by indicating a particular OID, single arrays can be updated.
An update can be complete in that the whole array is replaced or
partial, i.e., only part of the database array is changed. Only those
array cells are affected the spatial domain of the replacement
expression on the right-hand side of the set clause. Pixel locations are
matched pairwise according to the arrays’ spatial domains. Therefore, to
appropriately position the replacement array, application of the shift()
function (see Shifting a Spatial Domain) can be necessary; for more details and practical
examples continue to Partial Updates.
As a rule, the spatial domain of the righthand side expression must be equal to or a subset of the database array’s spatial domain.
Cell values contained in the update null set will not overwrite existing cell values which are not null. The update null set is taken from the source MDD if it is not empty, otherwise it will be taken from the target MDD.
Syntax
update collName as collIterator
set updateSpec assign mddExp
update collName as collIterator
set updateSpec assign mddExp
where booleanExp
where updateSpec can optionally contain a restricting minterval (see examples further below):
var
var [ mintervalExp ]
Each element of the set named collName which fulfils the selection predicate booleanEpxr gets assigned the result of mddExp. The right-hand side mddExp overwrites the corresponding area in the collection element; note that no automatic shifting takes place: the spatial domain of mddExp determines the very place where to put it.
If you want to include existing data from the database in mddExp, then this
needs to be specified in an additional from clause, just like in normal
select queries. The syntax in this case is
update collName as collIterator
set updateSpec assign mddExp
from existingCollName [ as collIterator ]
[, existingCollName [ as collIterator ] ] ...
where booleanExp
Example
An arrow marker is put into the image in collection mr2. The appropriate
part of a is selected and added to the arrow image which, for
simplicity, is assumed to have the appropriate spatial domain.
Figure 4.21 Original image of collection mr2¶
update mr2 as a
set a assign a[0 : 179 , 0:54] + $1/2c
The argument $1 is the arrow image (Figure 4.22) which has to be shipped to the server along with the query. It is an image showing a white arrow on a black background. For more information on the use of $ variables you may want to consult the language binding guides of the rasdaman Documentation Set.

Figure 4.22 Arrow used for updating¶
Looking up the mr2 collection after executing the update yields the result as shown in Figure 4.23:

Figure 4.23 Updated collection mr2¶
Note
The replacement expression and the MDD to be updated (i.e., left and right-hand side of the assign clause) in the above example must have the same dimensionality. Updating a (lower-dimensional) section of an MDDs can be achieved through a section operator indicating the “slice” to be modified. The following query appends one line to a fax (which is assumed to be extensible in the second dimension):
update fax as f
set f[ *:* , sdom(f)[1].hi+1 ] assign $1
The example below updates target collection mr2 with data from rgb
(collection that exists already in the database):
update mr2 as a
set a assign b[ 0:150, 50:200 ].red
from rgb as b
4.16.4.1. Partial Updates¶
Often very large data files need to be inserted in rasdaman, which don’t fit in main memory. One way to insert such a large file is to split it into smaller parts, and then import each part one by one via partial updates, until the initial image is reconstructed in rasdaman.
This is done in two steps: initializing an MDD in a collection, and inserting each part in this MDD.
4.16.4.1.1. Initialization¶
Updates replace an area in a target MDD object with the data from a source MDD object, so first the target MDD object needs to be initialized in a collection. To initialize an MDD object it’s sufficient to insert an MDD object of size 1 (a single point) to the collection:
insert into Coll
values marray it in [0:0,0:0,...] values 0
Note that the MDD constructed with the marray constructor should match the type of Coll (dimension and base type). If the dimension of the data matches the Coll dimensions (e.g. both are 3D), then inserting some part of the data would work as well. Otherwise, if data is 2D and Coll is 3D for example, it is necessary to initialize an array in the above way.
4.16.4.1.2. Updates¶
After we have an MDD initialized in the collection, we can continue with updating it with the individual parts using the update statement in rasql.
Refering to the update statement syntax, mddExp can
be any expression that results in an MDD object M, like an marray construct, a
format conversion function, etc. The position where M will be placed in the
target MDD (collIterator) is determined by the spatial domain of M. When
importing data in some format via the decode function, by default the resulting
MDD has an sdom of [0:width,0:height,..], which will place M at [0,0,..]
in the target MDD. In order to place it in a different position, the spatial
domain of M has to be explicitly set with the shift function in the query. For
example:
update Coll as c set c
assign shift(decode($1),[100,100])
The update statement allows one to dynamically expand MDDs (up to the limits of the MDD type if any have been specified), so it’s not necessary to fully materialize an MDD.
When the MDD is first initialized with:
insert into Coll
values marray it in [0:0,0:0,...] values 0
it has a spatial domain of [0:0,0:0,...] and only one point is materialized
in the database. Updating this MDD later on, further expands the spatial domain
if the source array M extends outside the sdom of target array T.
4.16.4.1.3. Example: 3D timeseries¶
Create a 3D collection first for arrays of type float:
create collection Coll FloatSet3
Initialize an array with a single cell in the collection:
insert into Coll
values marray it in [0:0,0:0,0:0] values 0f
Update array with data at the first time slice:
update Coll as c set c[0,*:*,*:*]
assign decode($1)
Update array with data at the second time slice, but shift spatially to
[10,1]:
update Coll as c set c[1,*:*,*:*]
assign shift( decode($1), [10,1] )
And so on.
4.16.4.1.4. Example: 3D cube of multiple 3D arrays¶
In this case we build a 3D cube by concatenating multiple smaller 3D cubes along a certain dimension, i.e. build a 3D mosaic.
Create the 3D collection first (suppose it’s for arrays of type float):
create collection Coll FloatSet3
Initialize an array with a single cell in the collection:
insert into Coll
values marray it in [0:0,0:0,0:0] values 0f
Update array with the first cube, which has itself sdom [0:3,0:100,0:100]:
update Coll as c set c[0:3,0:100,0:100]
assign decode($1, "netcdf")
After this Coll has sdom [0:3,0:100,0:100].
Update array with the second cube, which has itself sdom [0:5,0:100,0:100];
note that now we want to place this one on top of the first one with respect to
the first dimension, so its origin must be shifted by 5 so that its sdom will be
in effect [5:10,0:100,0:100]:
update Coll as c set c[5:10,0:100,0:100]
assign shift(decode($1, "netcdf"), [5,0,0])
The sdom of Coll is now [0:10,0:100,0:100].
Update array with the third cube, which has itself sdom [0:2,0:100,0:100];
note that now we want to place this one next to the first two with respect to
the second dimension and a bit higher by 5 pixels, so that its sdom will be in
effect [5:7,100:200,0:100]:
update Coll as c set c[5:7,100:200,0:100]
assign shift(decode($1, "netcdf"), [5,100,0])
The sdom of Coll is now [0:10,100:200,0:100].
4.16.4.2. Tiling Update¶
The update statement in rasdaman offers the functionality to modify the tiling configuration of MDD objects within a collection. This manipulation can be applied overall to all MDDs in a collection, or selectively, by using the where clause to affect specific arrays.
4.16.4.2.1. Syntax¶
The syntax for the update operation involving tiling is as follows:
update collName as collIterator
mddConfiguration
update collName as collIterator
mddConfiguration
where generalExp
Each element of the set collName which fulfils the selection predicate booleanEpxr (or all elements in the absence of the where clause) is retiled based on the tiling configuration specified in mddConfiguration.
4.16.4.2.2. Examples¶
The following examples demonstrate the usage of the update statement for tiling.
To update the tiling configuration of all MDDs in a collection, you can use:
update MyCollection
tiling
area of interest [0:20,0:40],[45:80,80:85]
tile size 1000000
To update the tiling configuration of selected MDDs in a collection based on a condition, you can use:
update MyCollection
tiling
regular [ 256 : 256 ]
where oid( MyCollection ) = 337
For additional details on tiling, different tiling methods and how to work with tiling configurations, refer to the Storage Layout Language of the documentation.
4.16.5. Delete¶
Arrays are deleted from a database collection using the delete statement. The arrays to be removed from a collection can be further characterized in an optional where clause. If the condition is omitted, all elements will be deleted so that the collection will be empty afterwards.
Syntax
delete from collName [ as collIterator ]
[ where booleanExp ]
Example
delete from mr1 as a
where all_cells( a < 30 )
This will delete all “very dark” images of collection mr1 with all pixel
values lower than 30.
4.17. Transaction Scheduling¶
Since rasdaman 9.0, database transactions lock arrays on fine-grain level. This prevents clients from changing array areas currently being modified by another client.
4.17.1. Locking¶
Lock compatibility is as expected: read access involves shared (“S”) locks which are mutually compatible while write access imposes an exclusive lock (“X”) which prohibits any other access:
S |
X |
|
S |
+ |
- |
X |
- |
- |
Shared locks are set by SELECT queries, exclusive ones in INSERT,
UPDATE, and DELETE queries.
Locks are acquired by queries dynamically as needed during a transaction. All locks are held until the end of the transaction, and then released collectively 15.
4.17.2. Lock Granularity¶
The unit of locking is a tile, as tiles also form the unit of access to persistent storage.
4.17.3. Conflict Behavior¶
If a transaction attempts to acquire a lock on a tile which has an incompatible lock it will abort with a message similar to the following:
Error: One or more of the target tiles are locked by another
transaction.
Only the query will return with an exception, the rasdaman transaction as such is not affected. It is up to the application program to catch the exception and react properly, depending on the particular intended behaviour.
4.17.4. Lock Federation¶
Locks are maintained in the PostgreSQL database in which rasdaman stores data. Therefore, all rasserver processes accessing the same RASBASE get synchronized.
4.17.5. Examples¶
The following two SELECT queries can be run concurrently against the same database:
rasql -q "select mr[0:10,0:10] from mr"
rasql -q "select mr[5:10,5:10] from mr"
The following two UPDATE queries can run concurrently as well, as they address different collections:
rasql -q "update mr set mr[0:10,0:10] \
assign marray x in [0:10,0:10] values 127c" \
--user rasadmin --passwd rasadmin
rasql -q "update mr2 set mr2[0:5,0:5] \
assign marray x in [0:5,0:5] values 65c" \
--user rasadmin --passwd rasadmin
From the following two queries, one will fail (the one which happens to arrive later) because the address the same tile:
rasql -q "update mr set mr[0:10,0:10] assign \
marray x in [0:10,0:10] values 127c" \
--user rasadmin --passwd rasadmin
rasql -q "update mr set mr[0:5,0:5] assign \
marray x in [0:5,0:5] values 65c" \
--user rasadmin --passwd rasadmin
4.17.6. Limitations¶
Currently, only tiles are locked, not other entities like indexes.
4.18. Linking MDD with Other Data¶
4.18.1. Purpose of OIDs¶
Each array instance and each collection in a rasdaman database has a identifier which is unique within a database. In the case of a collection this is the collection name and an object identifier (OID), whereas for an array this is only the OID. OIDs are generated by the system upon creation of an array instance, they do not change over an array’s lifetime, and OIDs of deleted arrays will never be reassigned to other arrays. This way, OIDs form the means to unambiguously identifiy a particular array. OIDs can be used several ways:
In rasql, OIDs of arrays can be retrieved and displayed, and they can be used as selection conditions in the condition part.
OIDs form the means to establish references from objects or tuples residing in other databases systems to rasdaman arrays. Please refer for further information to the language-specific rasdaman Developer’s Guides and the rasdaman External Products Integration Guide available for each database system to which rasdaman interfaces.
Due to the very different referencing mechanisms used in current database technology, there cannot be one single mechanism. Instead, rasdaman employs its own identification scheme which, then, is combined with the target DBMS way of referencing. See Object identifier (OID) Constants of this document as well as the rasdaman External Products Integration Guide for further information.
4.18.2. Collection Names¶
MDD collections are named. The name is indicated by the user or the application program upon creation of the collection; it must be unique within the given database. The most typical usage forms of collection names are
as a reference in the from clause of a rasql query
their storage in an attribute of a base DBMS object or tuple, thereby establishing a reference (also called foreign key or pointer).
4.18.3. Array Object identifiers¶
Each MDD array is world-wide uniquely identified by its object identifier (OID). An OID consists of three components:
A string containing the system where the database resides (system name),
A string containing the database (base name), and
A number containing the local object id within the database.
The main purposes of OIDs are
to establish references from the outside world to arrays and
to identify a particular array by indicating one OID or an OID list in the search condition of a query.
4.19. Storage Layout Language¶
4.19.1. Overview¶
Tiling
To handle arbitrarily large arrays, rasdaman introduces the concept of tiling them, that is: partitioning a large array into smaller, non-overlapping sub-arrays which act as the unit of storage access during query evaluation. To the query client, tiling remains invisible, hence it constitutes a tuning parameter which allows database designers and administrators to adapt database storage layout to specific query patterns and workloads.
To this end, rasdaman offers a storage layout language for arrays which embeds into the query language and gives users comfortable, yet concise control over important physical tuning parameters. Further, this sub-language wraps several strategies which turn out useful in face of massive spatio-temporal data sets.
Tiling can be categorized into aligned and non-aligned (Figure 4.24).A tiling is aligned if tiles are defined through axis-parallel hyperplanes cutting all through the domain. Aligned tiling is further classified into regular and aligned irregular depending on whether the parallel hyperplanes are equidistant (except possibly for border tiles) or not. The special case of equally sized tile edges in all directions is called cubed.
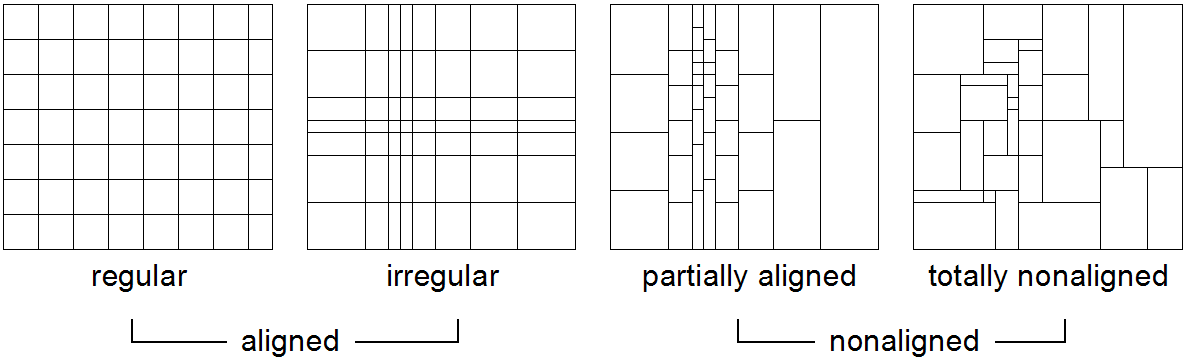
Figure 4.24 Types of tilings¶
Non-aligned tiling contains tiles whose faces are not aligned with those of their neighbors. This can be partially aligned with still some hyperplanes shared or totally non-aligned with no such sharing at all.
Syntax
We use a BNF variant where optional elements are indicated as
( ... )?
to clearly distinguish them from the “[” and “]” terminals.
Tiling Through API
In the rasdaman C++ API (cf. C++ Guide), this functionality is available through a specific hierarchy of classes.
Introductory Example
The following example illustrates the overall syntax extension which the storage layout sublanguage adds to the insert statement:
insert into MyCollection
values ...
tiling
area of interest [0:20,0:40],[45:80,80:85]
tile size 1000000
4.19.2. General Tiling Parameters¶
Maximum Tile Size
The optional tile size parameter allows specifying a maximum tile size; irrespective of the algorithm employed to obtain a particular tile shape, its size will never exceed the maximum indicated in this parameter.
Syntax:
tile size t
where t indicates the tile size in bytes.
If nothing is known about the access patterns, tile size allows streamlining array tiling to architectural parameters of the server, such as DMA bandwidth and disk speed.
Tile Configuration
A tile configuration is a list of bounding boxes specified by their extent. No position is indicated, as it is the shape of the box which will be used to define the tiling, according to various strategies.
Syntax:
[ integerLit , ... , integerLit ]
For a d-dimensional MDD, the tile configuration consists of a vector
of d elements where the ith vector specifies the tile
extent in dimension i, for 0lei<d. Each number indicates the
tile extent in cells along the corresponding dimension.
For example, a tile configuration [100, 100, 1000] for a 3-D MDD states
that tiles should have an extent of 100 cells in dimension 0 and 1, and
an extent of 1,000 cells in dimension 2. In image timeseries analysis,
such a stretching tiles along the time axis speeds up temporal analysis.
4.19.3. Regular Tiling¶
Concept
Regular tiling applies when there is some varying degree of knowledge about the subsetting patterns arriving with queries. We may or may not know the lower corner of the request box, the size of the box, or the shape (i.e., edge size ratio) of the box. For example, map viewing clients typically send several requests of fixed extent per mouse click to maintain a cache of tiles in the browser for faster panning. So the extent of the tile is known – or at least that tiles are quadratic. The absolute location often is not known, unless the client is kind enough to always request areas only in one fixed tile size and with starting points in multiples of the tile edge length.If additionally the configuration follows a uniform probability distribution then a cubed tiling is optimal.
In the storage directive, regular tiling is specified by providing a bounding box list, TileConf, and an optional maximum tile size:
Syntax
tiling regular TileConf ( tile size integerLit )?
Example
This line below dictates, for a 2-D MDD, tiles to be of size 1024 x 1024, except for border tiles (which can be smaller):
tiling regular [ 1024 , 1024 ]
4.19.4. Aligned Tiling¶
Concept
Generalizing from regular tiling, we may not know a good tile shape for all dimensions, but only some of them. An axis pin { 1, …, d } which never participates in any subsetting box is called a preferred (or preferential) direction of access and denoted as tcp = *. An optimal tile structure in this situation extends to the array bounds in the preferential directions.
Practical use cases include satellite image time series stacks over some region. Grossly simplified, during analysis there are two distinguished access patterns (notwithstanding that others occur sometimes as well): either a time slice is read, corresponding to tc = (*, *, t) for some given time instance t, or a time series is extracted for one particular position (x, y) on the earth surface; this corresponds to tc = ( x, y, *). The aligned tiling algorithm creates tiles as large as possible based on the constraints that (i) tile proportions adhere to tc and (ii) all tiles have the same size. The upper array limits constitute an exception: for filling the remaining gap (which usually occurs) tiles can be smaller and deviate from the configuration sizings. Figure 4.25 illustrates aligned tiling with two examples, for configuration tc = (1, 2) (left) and for tc =(1, 3, 4) (right).
Figure 4.25 Aligned tiling examples¶
Preferential access is illustrated in Figure 4.26. Left, access is performed along preferential directions 1 and 2, corresponding to configuration tc = (*, *, 1). The tiling tothe right supports configuration tc = (4, 1, *) with preferred axis 3.
Figure 4.26 Aligned tiling examples with preferential access directions¶
The aligned tiling construction consists of two steps. First, a concrete tile shape is determined. After that, the extent of all tiles is calculated by iterating over the array’s complete domain. In presence of more than one preferred directions - i.e., with a configuration containing more than one “*” values - axes are prioritized in descending order. This exploits the fact that array linearization is performed in a way that the “outermost loop” is the first dimension and the “innermost loop” the last. Hence, by clustering along higher coordinate axes a better spatial clustering is achieved.
Syntax
tiling aligned TileConf ( tile size IntLit )?
Example
The following clause accommodates map clients fetching quadratic images known to be no more than 512 x 512 x 3 = 786,432 bytes:
tiling aligned [1,1] tile size 786432
Important
Aligned tiling is the default strategy in rasdaman.
4.19.5. Directional Tiling¶
Concept
Sometimes the application semantics prescribes access in well-known coordinate intervals. In OLAP, such intervals are given by the semantic categories of the measures as defined by the dimension hierarchies, such as product categories which are defined for the exact purpose of accessing them group-wise in queries. Similar effects can occur with spatio-temporal data where, for example, a time axis may suggest access in units of days, weeks, or years. In rasdaman, if bounding boxes are well known then spatial access may be approximated by those; if they are overlapping then this is a case for area-of-interest tiling (see below), if not then directional tiling can be applied.
The tiling corresponding to such a partition is given by its Cartesian product. Figure 4.27 shows such a structure for the 2-D and 3-D case.
To construct it, the partition vectors are used to span the Cartesian product first. Should one of the resulting tiles exceed the size limit, as it happens in the tiles marked with a “*” in Figure 4.27, then a so-called sub-tiling takes place. Sub-tiling applies regular tiling by introducing additional local cutting hyperplanes. As these hyperplanes do not stretch through all tiles the resulting tiling in general is not regular. The resulting tile set guarantees that for answering queries using one of the subsetting patterns in part, or any union of these patterns, only those cells are read which will be delivered in the response. Further, if the area requested is smaller than the tile size limit then only one tile needs to be accessed.
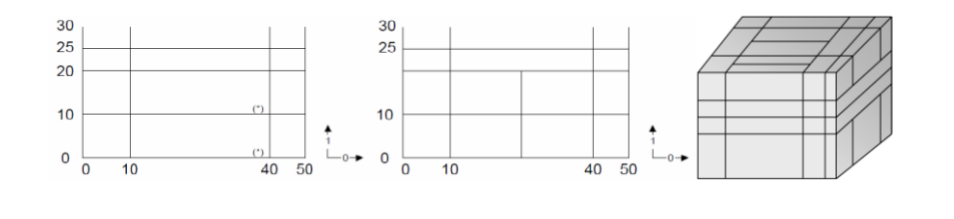
Figure 4.27 Directional tiling¶
Sometimes axes do not have categories associated. One possible reason is that subsetting is never performed along this axis, for example in an image time series where slicing is done along the time axis while the x/y image planes always are read in total. Similarly, for importing 4-D climate data into a GIS a query might always slice at the lowest atmospheric layer and at the most current time available without additional trimming in the horizontal axes.
We call such axes preferred access directions in the context of a directional tiling; they are identified by empty partitions. To accommodate this intention expressed by the user the sub-tiling strategy changes: no longer is regular tiling applied, which would introduce undesirable cuts along the preferred axis, but rather are subdividing hyperplanes constructed parallel to the preference axis. This allows accommodating the tile size maximum while, at the same time, keeping the number of tiles accessed in preference direction at a minimum.
In Figure 4.28, a 3-D cube is first split by way of directional tiling (left). One tile is larger than the maximum allowed, hence sub-tiling starts (center). It recognizes that axes 0 and 2 are preferred and, hence, splits only along dimension 1. The result (right) is such that subsetting along the preferred axes - i.e., with a trim or slice specification only in dimension 1 - can always be accommodated with a single tile read.

Figure 4.28 Directional tiling of a 3-D cube with one degree of freedom¶
Syntax
tiling directional splitList
( with subtiling ( tile size integerLit)? )?
where splitList is a list of split vectors (t1,1; …; t1,n1),…,(td,1; …; td,nd). Each split vector consists of an ascendingly ordered list of split points for the tiling algorithm, or an asterisk “*” for a preferred axis. The split vectors are positional, applying to the dimension axes of the array in order of appearance.
Example
The following defines a directional tiling with split vectors (0; 512; 1) and (0; 15; 200) for axes 0 and 2, respectively, with dimension 1 as a preferred axis:
tiling directional [0,512,1024], [], [0,15,200]
4.19.6. Area of Interest Tiling¶
Concept
An area of interest is a frequently accessed sub-array of an array object. An area-of-interest pattern, consequently, consists of a set of domains accessed with an access probability significantly higher than that of all other possible patterns. Goal is to achieve a tiling which optimizes access to these preferred patterns; performance of all other patterns is ignored.
These areas of interest do not have to fully cover the array, and the may overlap. The system will establish an optimal disjoint partitioning for the given boxes in a way that the amount of data and the number of tiles accessed for retrieval of any area of interest are minimized. More exactly, it is guaranteed that accessing an area of interest only reads data belonging to this area.
Figure 4.29 gives an intuition of how the algorithm works. Given some area-of-interest set (a), the algorithm first partitions using directional tiling based on the partition boundaries (b). By construction, each of the resulting tiles (c) contains only cells which all share the same areas of interest, or none at all. As this introduces fragmentation, a merge step follows where adjacent partitions overlapping with the same areas of interest are combined. Often there is more than one choice to perform merging; the algorithm is inherently nondeterministic. Rasdaman exploits this degree of freedom and cluster tiles in sequence of dimensions, as this represents the sequentialization pattern on disk and, hence, is the best choice for maintaining spatial clustering on disk (d,e). In a final step, sub-tiling is performed on the partitions as necessary, depending on the tile size limit. In contrast to the directional tiling algorithm, an aligned tiling strategy is pursued here making use of the tile configuration argument, tc. As this does not change anything in our example, the final result (f) is unchanged over (e).
Figure 4.29 Steps in performing area of interest tiling**¶
Syntax
tiling area of interest tileConf ( tile size integerLit )?
Example
tiling area of interest
[0:20,0:40],[945:980,980:985],[10:1000,10:1000]
4.19.7. Tiling statistic¶
Concept
Area of interest tiling requires enumeration of a set of clearly delineated areas. Sometimes, however, retrieval does not follow such a focused pattern set, but rather shows some random behavior oscillating around hot spots. This can occur, for example, when using a pointing device in a Web GIS: while many users possibly want to see some “hot” area, coordinates submitted will differ to some extent. We call such a pattern multiple accesses to areas of interest. Area of interest tiling can lead to significant disadvantages in such a situation. If the actual request box is contained in some area of interest then the corresponding tiles will have to be pruned from pixels outside the request box; this requires a selective copying which is significantly slower than a simple memcpy(). More important, however, is a request box going slightly over the boundaries of the area of interest - in this case, an additional tile has to be read from which only a small portion will be actually used. Disastrous, finally, is the output of the area-of-interest tiling, as an immense number of tiny tiles will be generated for all the slight area variations, leading to costly merging during requests.
This motivates a tiling strategy which accounts for statistically blurred access patterns. The statistic tiling algorithm receives a list of access patterns plus border and frequency thresholds. The algorithm condenses this list into a smallish set of patterns by grouping them according to similarity. This process is guarded by the two thresholds. The border threshold determines from what maximum difference on two areas are considered separately. It is measured in number of cells to make it independent from area geometry. The result is a reduced set of areas, each associated with a frequency of occurrence. In a second run, those areas are filtered out which fall below the frequency threshold. Having calculated such representative areas, the algorithm performs an area of interest tiling on these.
This method has the potential of reducing overall access costs provided thresholds are placed wisely. Log analysis tools can provide estimates for guidance. In the storage directive, statistical tiling receives a list of areas plus, optionally, the two thresholds and a tile size limit.
Syntax
tiling statistic tileConf
( tile size integerLit )?
( border threshold integerLit)?
( interest threshold floatLit)?
Example
The following example specifies two areas, a border threshold of 50 and an interest probability threshold of 30%:
tiling statistic [0:20,0:40],[30:50,70:90]
border threshold 50
interest threshold 0.3
4.19.8. Summary: Tiling Guidelines¶
This section summarizes rules of thumb for a good tiling. However, a thorough evaluation of the query access pattern, either empirically through server log inspection or theoretically by considering application logics, is strongly recommended, as it typically offers a potential for substantial improvements over the standard heuristics.
Nothing is known about access patterns: choose regular tiling with a maximum tile size; on PC-type architectures, tile sizes of about 4-5 MB have yielded good results.
Trim intervals in direction x are n times more frequent than in direction y and z together: choose directional tiling where the ratios are approximately x*n=y*z. Specify a maximum tile size.
Hot spots (i.e., their bounding boxes) are known: choose Area of Interest tiling on these bounding boxes.
4.20. Web Access to rasql¶
4.20.1. Overview¶
As part of petascope, the geo service frontend to rasdaman, Web access to rasql is provided. The request format is described in Request Format, the response format in Response Format below.
4.20.2. Service Endpoint¶
The service endpoint for rasql queries is
http://{service}/{path}/rasdaman/rasql
4.20.3. Request Format¶
A request is sent as an http GET URL with the query as key-value pair
parameter. By default, the rasdaman login is taken from the petascope
settings in petascope.properties; optionally, another valid rasdaman
user name and password can be provided as additional parameters.
Syntax
http://{service}/{path}/rasdaman/rasql?params
This servlet endpoint accepts KVP requests with the following parameters:
- query=q
where q is a valid rasql query, appropriately escaped as per http specification.
- username=u
where u is the user name for logging into rasdaman (optional, default: value of variable
rasdaman_userinpetascope.properties)- password=p
where p is the password for logging into rasdaman (optional, default: value of variable
rasdaman_passinpetascope.properties)
Example
The following URL sends a query request to a fictitious server www.acme.com:
http://www.acme.com/rasdaman?
query=select%20rgb.red+rgb.green%20from%20rgb
&username=rasguest
&password=rasguest
Since v10, this servlet endpoint can accept the credentials
for username:password in basic authentication headers and POST protocol,
for example using curl tool:
curl -u rasguest:rasguest
-d 'query=select 1 + 15 from test_mr as c'
'http://localhost:8080/rasdaman/rasql'
If results from rasql server are multiple objects
(e.g: SELECT .. FROM RAS_* or a collection contains multiple arrays),
then they are written in multipart/related MIME format with End
string as multipart boundary. Below is an example
from SELECT c from RAS_COLLECTIONNAMES as c:
Clients need to parse the multipart results for these cases. There are some useful libraries to do that, e.g. NodeJS with Mailparser.
4.20.4. Response Format¶
The response to a rasdaman query gets wrapped into a http message. The response format is as follows, depending on the nature of the result:
If the query returns arrays, then the MIME type of the response is
application/octet-stream.
If the result is empty, the document will be empty.
If the result consists of one array object, then this object will be delivered as is.
If the result consists of several array objects, then the response will consist of a Multipart/MIME document.
If the query returns scalars, all scalars will be delivered in one document of MIME type
text/plain, separated by whitespace.
4.20.5. Security¶
User and password are expected in cleartext, so do not use this tool in security sensitive contexts.
The service endpoint rasdaman/rasql, being part of the petascope
servlet, can be disabled in the servlet container’s setup (such as
Tomcat).
4.20.6. Limitations¶
Currently, no uploading of data to the server is supported. Hence,
functionality is restricted to queries without positional parameters $1,
$2, etc.
Currently, array responses returned invariably have the same MIME type,
application/octet-stream. In future it is foreseen to adjust the MIME
type to the identifier of the specific file format as chosen in the
encode() function.
4.21. Appendix A: rasql Grammar¶
This appendix presents a simplified list of the main rasql grammar rules
used in the rasdaman system. The grammar is described as a set of
production rules. Each rule consists of a non-terminal on the left-hand
side of the colon operator and a list of symbol names on the right-hand
side. The vertical bar | introduces a rule with the same left-hand
side as the previous one. It is usually read as or. Symbol names can
either be non-terminals or terminals (the former ones printed in bold
face as a link which can be followed to the non-terminal production).
Terminals represent keywords of the language, or identifiers, or
number literals; “(“, “)”, “[“, and “]” are also terminals, but
they are in double quotes to distinguish them from the grammar parentheses
(used to group alternatives) or brackets (used to indicate optional parts).
query ::=createExp|dropExp|selectExp|updateExp|insertExp|deleteExpcreateExp ::=createCollExp|createStructTypeExp|createMarrayTypeExp|createSetTypeExpcreateCollExp ::= create collectionnamedCollectiontypeNamecreateCellTypeExp ::= create typetypeNamecellTypeExpcellTypeExp ::= "("attributeNametypeName[ ,attributeNametypeName]... ")" createMarrayTypeExp ::= create typetypeNameas "("cellTypeExp|typeName")" mdarraydomainSpecdomainSpec ::= "["extentExpList"]" extentExpList ::=extentExp[ ,extentExpList] extentExp ::=axisName[ "("integerLit|intervalExp")" ] boundSpec ::=integerExpcreateSetTypeExp ::= create typetypeNameas set "("typeName")" "["nullExp"]" nullExp ::= null valuesmintervalExpdropExp ::= drop collectionnamedCollection| drop typetypeName
selectExp ::= selectresultListfromcollectionList[ wheregeneralExp] updateExp ::= updateiteratedCollectionsetupdateSpecassigngeneralExp[ wheregeneralExp] insertExp ::= insert intonamedCollectionvaluesgeneralExp[ tiling [StorageDirectives] ] StorageDirectives ::=RegularT|AlignedT|DirT|AoiT|StatTRegularT ::= regularTileConf[ tile sizeintegerLit] AlignedT ::= alignedTileConf[TileSize] DirT ::= directionalSplitList[ with subtiling [TileSize] ] AoiT ::= area of interestBboxList[TileSize] StatT ::= statisticTileConf[TileSize] [ border thresholdintegerLit] [ interest thresholdfloatLit] TileSize ::= tile sizeintegerLitTileConf ::=BboxList[ ,BboxList]... BboxList ::= "["integerLit:integerLit[ ,integerLit:integerLit]... "]" Index ::= indexIndexNamedeleteExp ::= delete fromiteratedCollection[ wheregeneralExp] updateSpec ::=variable[mintervalExp] resultList ::= [resultList, ]generalExp
generalExp ::=mddExp|trimExp|reduceExp|inductionExp|caseExp|functionExp|integerExp|condenseExp|variable|mintervalExp|intervalExp|generalLitmintervalExp ::= "["spatialOpList"]" | sdom "("collIterator")" intervalExp ::= (integerExp| * ) : (integerExp| * ) integerExp ::=integerTerm+integerExp|integerTerm-integerExp|integerTermintegerTerm ::=integerFactor*integerTerm|integerFactor/integerTerm|integerFactorintegerFactor ::=integerLit|identifier[structSelection] |mintervalExp. lo |mintervalExp. hi | "("integerExp")" spatialOpList ::=spatialOpList2spatialOpList2 ::=spatialOpList2,spatialOp|spatialOpspatialOp ::=generalExpcondenseExp ::= condensecondenseOpLitovercondenseVariableingeneralExp[ wheregeneralExp] usinggeneralExpcondenseOpLit ::= + | * | and | or | max | min functionExp ::= version "(" ")" |unaryFun"("collIterator")" |binaryFun"("generalExp,generalExp")" |transcodeExpunaryFun ::= oid | dbinfo binaryFun ::= shift | scale | bit | pow | power | div | mod transcodeExp ::= encode "("generalExp,StringLit[ ,StringLit] ")" | decode "(" $integerLit[ ,StringLit,StringLit] ")" | decode "("generalExp")" structSelection ::= . (attributeName|integerLitExp) inductionExp ::=unaryInductionOp"("generalExp")" |generalExp. ( re | im ) |generalExpstructSelection| notgeneralExp|generalExpbinaryInductionOpgeneralExp| ( + | - )generalExp| "("castType")"generalExp| "("generalExp")" unaryInductionOp ::= sqrt | abs | exp | log | ln | sin | cos | tan | sinh | cosh | tanh | arcsin | arccos | arctan | ceil | floor | round binaryInductionOp ::= overlay | is | = | and | or | xor | plus | minus | mult | div| equal | < | > | <= | >= | != castType ::= bool | char | octet | short | long | ulong | float | double | ushort | unsigned ( short | long ) caseExp ::= case [generalExp]whenListelsegeneralExpend whenList ::= [whenList] whengeneralExpthengeneralExpcollectionList ::= [collectionList, ]iteratedCollectioniteratedCollection ::=namedCollection[ [ as ]collIterator] reduceExp ::=reduceIdent"("generalExp")" reduceIdent ::= all_cells | some_cells | count_cells | avg_cells | min_cells | max_cells | add_cells | stddev_samp | stddev_pop | var_samp | var_pop trimExp ::=generalExpmintervalExpmddExp ::= marrayivListvaluesgeneralExpivList ::= [ivList, ]marrayVariableingeneralExpgeneralLit ::=scalarLit|mddLit|StringLit|oidLitoidLit ::= <StringLit> mddLit ::= <mintervalExpdimensionLitList> | $integerLitdimensionLitList ::= [dimensionLitList; ]scalarLitListscalarLitList ::= [scalarLitList, ]scalarLitscalarLit ::=complexLit|atomicLitcomplexLit ::= [ struct ] {scalarLitList} atomicLit ::=booleanLit|integerLit|floatLit| complex "("floatLit,floatLit")" | complex "("integerLit,integerLit")" typeName ::=identifiervariable ::=identifiernamedCollection ::=identifiercollIterator ::=identifierattributeName ::=identifiermarrayVariable ::=identifiercondenseVariable ::=identifieridentifier ::= [a-zA-Z_] [a-zA-Z0-9_]*
4.22. Appendix B: Reserved keywords¶
This appendix presents the list of all tokens that CANNOT be used as variable names in rasql.
//.* |
–.* |
complex |
re |
im |
struct |
fastscale |
members |
add |
alter |
list |
select |
from |
where |
as |
restrict |
to |
extend |
by |
project |
near |
bilinear |
cubic |
cubicspline |
lanczos |
average |
mode |
med |
q1 |
q3 |
at |
dimension |
all_cell|all_cells |
some_cell|some_cells |
count_cell|count_cells |
add_cell|add_cells |
avg_cell|avg_cells |
min_cell|min_cells |
max_cell|max_cells |
var_pop |
var_samp |
stddev_pop |
stddev_samp |
sdom |
over |
overlay |
using |
lo |
hi |
concat |
along |
case |
when |
then |
else |
end |
insert |
into |
values |
delete |
drop |
create |
collection |
type |
update |
set |
assign |
in |
marray |
mdarray |
condense |
null |
commit |
oid |
shift |
clip |
subspace |
multipolygon |
projection |
polygon |
curtain |
corridor |
linestring |
coordinates |
multilinestring |
discrete |
range |
scale |
dbinfo |
version |
div |
mod |
is |
not |
sqrt |
tiff |
bmp |
hdf |
netcdf |
jpeg |
csv |
png |
vff |
tor |
dem |
encode |
decode |
inv_tiff |
inv_bmp |
inv_hdf |
inv_netcdf |
inv_jpeg |
inv_csv |
inv_png |
inv_vff |
inv_tor |
inv_dem |
inv_grib |
abs |
exp |
pow |
power |
log |
ln |
sin |
cos |
tan |
sinh |
cosh |
tanh |
arcsin |
asin |
arccos |
acos |
arctan |
atan |
index |
rc_index |
tc_index |
a_index |
d_index |
rd_index |
rpt_index |
rrpt_index |
it_index |
auto |
tiling |
aligned |
regular |
directional |
with |
subtiling |
no_limit |
regroup |
regroup_and_subtiling |
area |
of |
interest |
statistic |
tile |
size |
border |
threshold |
unsigned |
bool |
char |
octet |
short |
ushort |
long |
ulong |
float |
double |
CFloat32 |
CFloat64 |
CInt16 |
CInt32 |
nan |
nanf |
inf |
inff |
max |
min |
bit |
and |
or |
xor |
sort |
flip |
asc |
desc |
ceil |
floor |
round |
arctan2 |